жөӢиҜ•жӮЁзҡ„дёҡеҠЎ еҲҶй’ҹ
еҲӣе»әжӮЁзҡ„иҙҰжҲ·е№¶еңЁеҮ еҲҶй’ҹеҶ…еҗҜеҠЁжӮЁзҡ„AIиҒҠеӨ©жңәеҷЁдәәгҖӮе®Ңе…ЁеҸҜе®ҡеҲ¶пјҢж— йңҖзј–з Ғ - з«ӢеҚіејҖе§Ӣеҗёеј•жӮЁзҡ„е®ўжҲ·пјҒ
еҮ еҲҶй’ҹеҚіеҸҜе°ұз»Ә
ж— йңҖзј–з Ғ
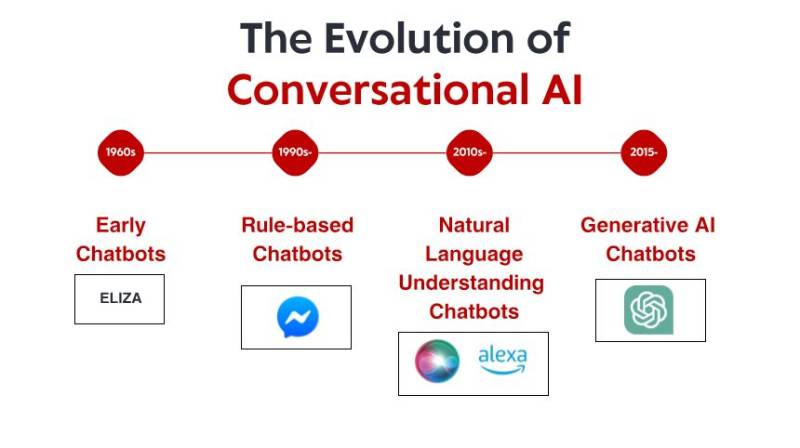
еҚ‘еҫ®зҡ„ејҖз«Ҝпјҡж—©жңҹеҹәдәҺ规еҲҷзҡ„зі»з»ҹ
еҜ№иҜқејҸдәәе·ҘжҷәиғҪзҡ„ж•…дәӢе§ӢдәҺ 20 дё–зәӘ 60 е№ҙд»ЈпјҢиҝңж—©дәҺжҷәиғҪжүӢжңәе’ҢиҜӯйҹіеҠ©жүӢжҲҗдёә家еәӯеҝ…йңҖе“Ғд№ӢеүҚгҖӮеңЁйә»зңҒзҗҶе·ҘеӯҰйҷўзҡ„дёҖдёӘе°Ҹе®һйӘҢе®ӨйҮҢпјҢи®Ўз®—жңә科еӯҰ家 Joseph Weizenbaum еҲӣйҖ дәҶиў«и®ёеӨҡдәәи®ӨдёәжҳҜ第дёҖдёӘиҒҠеӨ©жңәеҷЁдәәзҡ„ ELIZAгҖӮELIZA зҡ„и®ҫи®ЎеҲқиЎ·жҳҜжЁЎд»ҝзҪ—жқ°ж–ҜејҸзҡ„еҝғзҗҶжІ»з–—еёҲпјҢе®ғйҖҡиҝҮз®ҖеҚ•зҡ„жЁЎејҸеҢ№й…Қе’ҢжӣҝжҚўи§„еҲҷиҝӣиЎҢе·ҘдҪңгҖӮеҪ“з”ЁжҲ·иҫ“е…ҘвҖңжҲ‘ж„ҹеҲ°жӮІдјӨвҖқж—¶пјҢELIZA еҸҜиғҪдјҡеӣһзӯ”вҖңдҪ дёәд»Җд№Ҳж„ҹеҲ°жӮІдјӨпјҹвҖқвҖ”вҖ”йҖҡиҝҮе°ҶиҜӯеҸҘйҮҚж–°иЎЁиҝ°дёәй—®йўҳпјҢиҗҘйҖ еҮәдёҖз§ҚзҗҶи§Јзҡ„еҒҮиұЎгҖӮ
ELIZA зҡ„йқһеҮЎд№ӢеӨ„并йқһеңЁдәҺе…¶жҠҖжңҜеӨҚжқӮжҖ§вҖ”вҖ”д»Ҙд»ҠеӨ©зҡ„ж ҮеҮҶжқҘзңӢпјҢиҝҷдёӘзЁӢеәҸжһҒе…¶еҹәзЎҖгҖӮиҖҢжҳҜеңЁдәҺе®ғеҜ№з”ЁжҲ·дә§з”ҹзҡ„ж·ұиҝңеҪұе“ҚгҖӮе°Ҫз®Ўдәә们зҹҘйҒ“иҮӘе·ұжӯЈеңЁдёҺдёҖдёӘж— жі•зңҹжӯЈзҗҶи§Јзҡ„и®Ўз®—жңәзЁӢеәҸеҜ№иҜқпјҢдҪҶи®ёеӨҡдәәд»Қ然дёҺ ELIZA е»әз«ӢдәҶжғ…ж„ҹиҒ”зі»пјҢеҲҶдә«ж·ұеҲ»зҡ„дёӘдәәжғіжі•е’Ңж„ҹеҸ—гҖӮиҝҷз§ҚзҺ°иұЎи®© Weizenbaum жң¬дәәж„ҹеҲ°дёҚе®үпјҢе®ғжҸӯзӨәдәҶдәәзұ»еҝғзҗҶеӯҰзҡ„дёҖдәӣеҹәжң¬еҺҹзҗҶпјҢд»ҘеҸҠжҲ‘们д№җдәҺе°ҶеҚідҪҝжҳҜжңҖз®ҖеҚ•зҡ„еҜ№иҜқз•ҢйқўжӢҹдәәеҢ–зҡ„еҖҫеҗ‘гҖӮ
еңЁж•ҙдёӘ 20 дё–зәӘ 70 е№ҙд»Је’Ң 80 е№ҙд»ЈпјҢеҹәдәҺ规еҲҷзҡ„иҒҠеӨ©жңәеҷЁдәәжІҝиўӯдәҶ ELIZA зҡ„жЁЎжқҝпјҢ并дёҚж–ӯж”№иҝӣгҖӮеғҸ PARRYпјҲжЁЎжӢҹеҒҸжү§еһӢзІҫзҘһеҲҶиЈӮз—ҮжӮЈиҖ…пјүе’Ң RACTERпјҲе…¶вҖңж’°еҶҷвҖқдәҶдёҖжң¬еҗҚдёәгҖҠиӯҰеҜҹзҡ„иғЎйЎ»жҳҜеҚҠжҲҗе“ҒгҖӢзҡ„д№Ұпјүиҝҷж ·зҡ„зЁӢеәҸд»Қ然зүўзүўең°йҒөеҫӘзқҖеҹәдәҺ规еҲҷзҡ„иҢғејҸвҖ”вҖ”дҪҝз”Ёйў„е®ҡд№үзҡ„жЁЎејҸгҖҒе…ій”®иҜҚеҢ№й…Қе’ҢжЁЎжқҝеҢ–е“Қеә”гҖӮ
иҝҷдәӣж—©жңҹзі»з»ҹеӯҳеңЁдёҘйҮҚзҡ„еұҖйҷҗжҖ§гҖӮе®ғд»¬ж— жі•зңҹжӯЈзҗҶи§ЈиҜӯиЁҖпјҢж— жі•д»ҺдәӨдә’дёӯеӯҰд№ пјҢд№ҹж— жі•йҖӮеә”ж„ҸеӨ–зҡ„иҫ“е…ҘгҖӮе®ғ们зҡ„зҹҘиҜҶд»…йҷҗдәҺзЁӢеәҸе‘ҳжҳҺзЎ®е®ҡд№үзҡ„规еҲҷгҖӮеҪ“з”ЁжҲ·дёҚеҸҜйҒҝе…Қең°и¶…еҮәиҝҷдәӣз•Ңйҷҗж—¶пјҢжҷәиғҪзҡ„е№»иұЎеҫҲеҝ«е°ұдјҡз ҙзҒӯпјҢжҸӯзӨәеҮәе…¶иғҢеҗҺзҡ„жңәжў°жң¬иҙЁгҖӮе°Ҫз®ЎеӯҳеңЁиҝҷдәӣйҷҗеҲ¶пјҢиҝҷдәӣе…Ҳй©ұзі»з»ҹд»Қ然дёәжүҖжңүжңӘжқҘеҜ№иҜқејҸдәәе·ҘжҷәиғҪеҘ е®ҡдәҶеҹәзЎҖгҖӮ
ELIZA зҡ„йқһеҮЎд№ӢеӨ„并йқһеңЁдәҺе…¶жҠҖжңҜеӨҚжқӮжҖ§вҖ”вҖ”д»Ҙд»ҠеӨ©зҡ„ж ҮеҮҶжқҘзңӢпјҢиҝҷдёӘзЁӢеәҸжһҒе…¶еҹәзЎҖгҖӮиҖҢжҳҜеңЁдәҺе®ғеҜ№з”ЁжҲ·дә§з”ҹзҡ„ж·ұиҝңеҪұе“ҚгҖӮе°Ҫз®Ўдәә们зҹҘйҒ“иҮӘе·ұжӯЈеңЁдёҺдёҖдёӘж— жі•зңҹжӯЈзҗҶи§Јзҡ„и®Ўз®—жңәзЁӢеәҸеҜ№иҜқпјҢдҪҶи®ёеӨҡдәәд»Қ然дёҺ ELIZA е»әз«ӢдәҶжғ…ж„ҹиҒ”зі»пјҢеҲҶдә«ж·ұеҲ»зҡ„дёӘдәәжғіжі•е’Ңж„ҹеҸ—гҖӮиҝҷз§ҚзҺ°иұЎи®© Weizenbaum жң¬дәәж„ҹеҲ°дёҚе®үпјҢе®ғжҸӯзӨәдәҶдәәзұ»еҝғзҗҶеӯҰзҡ„дёҖдәӣеҹәжң¬еҺҹзҗҶпјҢд»ҘеҸҠжҲ‘们д№җдәҺе°ҶеҚідҪҝжҳҜжңҖз®ҖеҚ•зҡ„еҜ№иҜқз•ҢйқўжӢҹдәәеҢ–зҡ„еҖҫеҗ‘гҖӮ
еңЁж•ҙдёӘ 20 дё–зәӘ 70 е№ҙд»Је’Ң 80 е№ҙд»ЈпјҢеҹәдәҺ规еҲҷзҡ„иҒҠеӨ©жңәеҷЁдәәжІҝиўӯдәҶ ELIZA зҡ„жЁЎжқҝпјҢ并дёҚж–ӯж”№иҝӣгҖӮеғҸ PARRYпјҲжЁЎжӢҹеҒҸжү§еһӢзІҫзҘһеҲҶиЈӮз—ҮжӮЈиҖ…пјүе’Ң RACTERпјҲе…¶вҖңж’°еҶҷвҖқдәҶдёҖжң¬еҗҚдёәгҖҠиӯҰеҜҹзҡ„иғЎйЎ»жҳҜеҚҠжҲҗе“ҒгҖӢзҡ„д№Ұпјүиҝҷж ·зҡ„зЁӢеәҸд»Қ然зүўзүўең°йҒөеҫӘзқҖеҹәдәҺ规еҲҷзҡ„иҢғејҸвҖ”вҖ”дҪҝз”Ёйў„е®ҡд№үзҡ„жЁЎејҸгҖҒе…ій”®иҜҚеҢ№й…Қе’ҢжЁЎжқҝеҢ–е“Қеә”гҖӮ
иҝҷдәӣж—©жңҹзі»з»ҹеӯҳеңЁдёҘйҮҚзҡ„еұҖйҷҗжҖ§гҖӮе®ғд»¬ж— жі•зңҹжӯЈзҗҶи§ЈиҜӯиЁҖпјҢж— жі•д»ҺдәӨдә’дёӯеӯҰд№ пјҢд№ҹж— жі•йҖӮеә”ж„ҸеӨ–зҡ„иҫ“е…ҘгҖӮе®ғ们зҡ„зҹҘиҜҶд»…йҷҗдәҺзЁӢеәҸе‘ҳжҳҺзЎ®е®ҡд№үзҡ„规еҲҷгҖӮеҪ“з”ЁжҲ·дёҚеҸҜйҒҝе…Қең°и¶…еҮәиҝҷдәӣз•Ңйҷҗж—¶пјҢжҷәиғҪзҡ„е№»иұЎеҫҲеҝ«е°ұдјҡз ҙзҒӯпјҢжҸӯзӨәеҮәе…¶иғҢеҗҺзҡ„жңәжў°жң¬иҙЁгҖӮе°Ҫз®ЎеӯҳеңЁиҝҷдәӣйҷҗеҲ¶пјҢиҝҷдәӣе…Ҳй©ұзі»з»ҹд»Қ然дёәжүҖжңүжңӘжқҘеҜ№иҜқејҸдәәе·ҘжҷәиғҪеҘ е®ҡдәҶеҹәзЎҖгҖӮ
зҹҘиҜҶйқ©е‘Ҫпјҡ专家系з»ҹе’Ңз»“жһ„еҢ–дҝЎжҒҜ
20 дё–зәӘ 80 е№ҙд»Је’Ң 90 е№ҙд»ЈеҲқпјҢ专家系з»ҹе…ҙиө·вҖ”вҖ”иҝҷдәӣдәәе·ҘжҷәиғҪзЁӢеәҸж—ЁеңЁйҖҡиҝҮжЁЎд»ҝзү№е®ҡйўҶеҹҹдәәзұ»дё“家зҡ„еҶізӯ–иғҪеҠӣжқҘи§ЈеҶіеӨҚжқӮй—®йўҳгҖӮиҷҪ然иҝҷдәӣзі»з»ҹжңҖеҲқ并йқһдёәеҜ№иҜқиҖҢи®ҫи®ЎпјҢдҪҶе®ғ们йҖҡиҝҮеј•е…ҘжӣҙеӨҚжқӮзҡ„зҹҘиҜҶиЎЁзӨәпјҢд»ЈиЎЁдәҶеҜ№иҜқејҸдәәе·ҘжҷәиғҪзҡ„йҮҚиҰҒиҝӣеҢ–жӯҘйӘӨгҖӮ
еғҸ MYCINпјҲз”ЁдәҺиҜҠж–ӯз»ҶиҸҢж„ҹжҹ“пјүе’Ң DENDRALпјҲз”ЁдәҺиҜҶеҲ«еҢ–еҗҲзү©пјүиҝҷж ·зҡ„专家系з»ҹе°ҶдҝЎжҒҜз»„з»ҮеҲ°з»“жһ„еҢ–зҹҘиҜҶеә“дёӯпјҢ并дҪҝз”ЁжҺЁзҗҶеј•ж“Һеҫ—еҮәз»“и®әгҖӮеҪ“еә”з”ЁдәҺеҜ№иҜқз•Ңйқўж—¶пјҢиҝҷз§Қж–№жі•дҪҝиҒҠеӨ©жңәеҷЁдәәиғҪеӨҹи¶…и¶Ҡз®ҖеҚ•зҡ„жЁЎејҸеҢ№й…ҚпјҢе®һзҺ°зұ»дјјжҺЁзҗҶзҡ„еҠҹиғҪвҖ”вҖ”иҮіе°‘еңЁзү№е®ҡйўҶеҹҹеҶ…жҳҜеҰӮжӯӨгҖӮ
дёҖдәӣе…¬еҸёејҖе§ӢдҪҝз”ЁиҝҷйЎ№жҠҖжңҜе®һзҺ°е®һйҷ…еә”з”ЁпјҢдҫӢеҰӮиҮӘеҠЁеҢ–е®ўжҲ·жңҚеҠЎзі»з»ҹгҖӮиҝҷдәӣзі»з»ҹйҖҡеёёдҪҝз”ЁеҶізӯ–ж ‘е’ҢеҹәдәҺиҸңеҚ•зҡ„дәӨдә’пјҢиҖҢдёҚжҳҜиҮӘз”ұеҪўејҸзҡ„еҜ№иҜқпјҢдҪҶе®ғ们代表дәҶе°Ҷд№ӢеүҚйңҖиҰҒдәәе·Ҙе№Ійў„зҡ„дәӨдә’иҮӘеҠЁеҢ–зҡ„ж—©жңҹе°қиҜ•гҖӮ
иҝҷдәӣзі»з»ҹд»Қ然еӯҳеңЁжҳҫи‘—зҡ„еұҖйҷҗжҖ§гҖӮиҝҷдәӣзі»з»ҹеҫҲи„ҶејұпјҢж— жі•дјҳйӣ…ең°еӨ„зҗҶж„ҸеӨ–иҫ“е…ҘгҖӮе®ғ们йңҖиҰҒзҹҘиҜҶе·ҘзЁӢеёҲд»ҳеҮәе·ЁеӨ§зҡ„еҠӘеҠӣжқҘжүӢеҠЁзј–з ҒдҝЎжҒҜе’Ң规еҲҷгҖӮжҲ–и®ёжңҖйҮҚиҰҒзҡ„жҳҜпјҢ他们д»Қз„¶ж— жі•зңҹжӯЈзҗҶи§ЈиҮӘ然иҜӯиЁҖзҡ„е…ЁйғЁеӨҚжқӮжҖ§е’ҢжЁЎзіҠжҖ§гҖӮ
е°Ҫз®ЎеҰӮжӯӨпјҢиҝҷдёӘж—¶д»ЈзЎ®з«ӢдәҶдёҖдәӣеҗҺжқҘеҜ№зҺ°д»ЈеҜ№иҜқејҸдәәе·ҘжҷәиғҪиҮіе…ійҮҚиҰҒзҡ„жҰӮеҝөпјҡз»“жһ„еҢ–зҹҘиҜҶиЎЁзӨәгҖҒйҖ»иҫ‘жҺЁзҗҶе’ҢйўҶеҹҹдё“дёҡеҢ–гҖӮе°Ҫз®ЎжҠҖжңҜе°ҡжңӘе®Ңе…ЁжҲҗзҶҹпјҢдҪҶиҢғејҸиҪ¬еҸҳзҡ„иҲһеҸ°е·Із»Ҹжҗӯе»әе®ҢжҜ•гҖӮ
еғҸ MYCINпјҲз”ЁдәҺиҜҠж–ӯз»ҶиҸҢж„ҹжҹ“пјүе’Ң DENDRALпјҲз”ЁдәҺиҜҶеҲ«еҢ–еҗҲзү©пјүиҝҷж ·зҡ„专家系з»ҹе°ҶдҝЎжҒҜз»„з»ҮеҲ°з»“жһ„еҢ–зҹҘиҜҶеә“дёӯпјҢ并дҪҝз”ЁжҺЁзҗҶеј•ж“Һеҫ—еҮәз»“и®әгҖӮеҪ“еә”з”ЁдәҺеҜ№иҜқз•Ңйқўж—¶пјҢиҝҷз§Қж–№жі•дҪҝиҒҠеӨ©жңәеҷЁдәәиғҪеӨҹи¶…и¶Ҡз®ҖеҚ•зҡ„жЁЎејҸеҢ№й…ҚпјҢе®һзҺ°зұ»дјјжҺЁзҗҶзҡ„еҠҹиғҪвҖ”вҖ”иҮіе°‘еңЁзү№е®ҡйўҶеҹҹеҶ…жҳҜеҰӮжӯӨгҖӮ
дёҖдәӣе…¬еҸёејҖе§ӢдҪҝз”ЁиҝҷйЎ№жҠҖжңҜе®һзҺ°е®һйҷ…еә”з”ЁпјҢдҫӢеҰӮиҮӘеҠЁеҢ–е®ўжҲ·жңҚеҠЎзі»з»ҹгҖӮиҝҷдәӣзі»з»ҹйҖҡеёёдҪҝз”ЁеҶізӯ–ж ‘е’ҢеҹәдәҺиҸңеҚ•зҡ„дәӨдә’пјҢиҖҢдёҚжҳҜиҮӘз”ұеҪўејҸзҡ„еҜ№иҜқпјҢдҪҶе®ғ们代表дәҶе°Ҷд№ӢеүҚйңҖиҰҒдәәе·Ҙе№Ійў„зҡ„дәӨдә’иҮӘеҠЁеҢ–зҡ„ж—©жңҹе°қиҜ•гҖӮ
иҝҷдәӣзі»з»ҹд»Қ然еӯҳеңЁжҳҫи‘—зҡ„еұҖйҷҗжҖ§гҖӮиҝҷдәӣзі»з»ҹеҫҲи„ҶејұпјҢж— жі•дјҳйӣ…ең°еӨ„зҗҶж„ҸеӨ–иҫ“е…ҘгҖӮе®ғ们йңҖиҰҒзҹҘиҜҶе·ҘзЁӢеёҲд»ҳеҮәе·ЁеӨ§зҡ„еҠӘеҠӣжқҘжүӢеҠЁзј–з ҒдҝЎжҒҜе’Ң规еҲҷгҖӮжҲ–и®ёжңҖйҮҚиҰҒзҡ„жҳҜпјҢ他们д»Қз„¶ж— жі•зңҹжӯЈзҗҶи§ЈиҮӘ然иҜӯиЁҖзҡ„е…ЁйғЁеӨҚжқӮжҖ§е’ҢжЁЎзіҠжҖ§гҖӮ
е°Ҫз®ЎеҰӮжӯӨпјҢиҝҷдёӘж—¶д»ЈзЎ®з«ӢдәҶдёҖдәӣеҗҺжқҘеҜ№зҺ°д»ЈеҜ№иҜқејҸдәәе·ҘжҷәиғҪиҮіе…ійҮҚиҰҒзҡ„жҰӮеҝөпјҡз»“жһ„еҢ–зҹҘиҜҶиЎЁзӨәгҖҒйҖ»иҫ‘жҺЁзҗҶе’ҢйўҶеҹҹдё“дёҡеҢ–гҖӮе°Ҫз®ЎжҠҖжңҜе°ҡжңӘе®Ңе…ЁжҲҗзҶҹпјҢдҪҶиҢғејҸиҪ¬еҸҳзҡ„иҲһеҸ°е·Із»Ҹжҗӯе»әе®ҢжҜ•гҖӮ
иҮӘ然иҜӯиЁҖзҗҶи§Јпјҡи®Ўз®—иҜӯиЁҖеӯҰзҡ„зӘҒз ҙ
20 дё–зәӘ 90 е№ҙд»Јжң«еҲ° 21 дё–зәӘеҲқпјҢиҮӘ然иҜӯиЁҖеӨ„зҗҶ (NLP) е’Ңи®Ўз®—иҜӯиЁҖеӯҰеҸ—еҲ°и¶ҠжқҘи¶ҠеӨҡзҡ„е…іжіЁгҖӮз ”з©¶дәәе‘ҳдёҚеҶҚиҜ•еӣҫдёәжҜҸз§ҚеҸҜиғҪзҡ„дәӨдә’жүӢеҠЁзј–еҶҷ规еҲҷпјҢиҖҢжҳҜејҖе§ӢејҖеҸ‘з»ҹи®Ўж–№жі•пјҢеё®еҠ©и®Ўз®—жңәзҗҶи§Јдәәзұ»иҜӯиЁҖзҡ„еӣәжңүжЁЎејҸгҖӮ
иҝҷз§ҚиҪ¬еҸҳеҫ—зӣҠдәҺеӨҡз§Қеӣ зҙ пјҡи®Ўз®—иғҪеҠӣзҡ„жҸҗеҚҮгҖҒз®—жі•зҡ„ж”№иҝӣпјҢд»ҘеҸҠиҮіе…ійҮҚиҰҒзҡ„пјҢеҸҜз”ЁдәҺеҲҶжһҗиҜӯиЁҖжЁЎејҸзҡ„еӨ§еһӢж–Үжң¬иҜӯж–ҷеә“зҡ„еҮәзҺ°гҖӮзі»з»ҹејҖе§ӢиһҚе…Ҙд»ҘдёӢжҠҖжңҜпјҡ
иҜҚжҖ§ж ҮжіЁпјҡиҜҶеҲ«иҜҚиҜӯзҡ„еҠҹиғҪжҳҜеҗҚиҜҚгҖҒеҠЁиҜҚгҖҒеҪўе®№иҜҚзӯүгҖӮ
е‘ҪеҗҚе®һдҪ“иҜҶеҲ«пјҡжЈҖжөӢе’ҢеҲҶзұ»дё“жңүеҗҚиҜҚпјҲдәәзү©гҖҒз»„з»ҮгҖҒең°зӮ№пјүгҖӮ
жғ…ж„ҹеҲҶжһҗпјҡзЎ®е®ҡж–Үжң¬зҡ„жғ…ж„ҹеҹәи°ғгҖӮ
иҜӯжі•еҲҶжһҗпјҡеҲҶжһҗеҸҘеӯҗз»“жһ„д»ҘиҜҶеҲ«иҜҚиҜӯд№Ӣй—ҙзҡ„иҜӯжі•е…ізі»гҖӮ
дёҖйЎ№жҳҫи‘—зҡ„зӘҒз ҙжқҘиҮӘ IBM зҡ„жІғжЈ®пјҢе®ғеңЁжҷәеҠӣз«һиөӣиҠӮзӣ®гҖҠеҚұйҷ©иҫ№зјҳпјҒгҖӢпјҲJeopardy!пјүдёӯеҮ»иҙҘдәҶдәәзұ»еҶ еҶӣгҖӮ 2011е№ҙгҖӮиҷҪ然дёҘж јжқҘиҜҙпјҢжІғ森并йқһдёҖдёӘеҜ№иҜқзі»з»ҹпјҢдҪҶе®ғеұ•зҺ°еҮәдәҶеүҚжүҖжңӘжңүзҡ„иғҪеҠӣпјҢиғҪеӨҹзҗҶи§ЈиҮӘ然иҜӯиЁҖй—®йўҳгҖҒжҗңзҙўжө·йҮҸзҹҘиҜҶеә“并еҪўжҲҗзӯ”жЎҲвҖ”вҖ”иҝҷдәӣиғҪеҠӣеҜ№дәҺдёӢдёҖд»ЈиҒҠеӨ©жңәеҷЁдәәиҮіе…ійҮҚиҰҒгҖӮ
е•Ҷдёҡеә”з”Ёд№ҹйҡҸд№ӢиҖҢжқҘгҖӮиӢ№жһңзҡ„SiriдәҺ2011е№ҙжҺЁеҮәпјҢе°ҶеҜ№иҜқз•ҢйқўеёҰз»ҷдәҶдё»жөҒж¶Ҳиҙ№иҖ…гҖӮиҷҪ然еҸ—еҲ°еҪ“д»Ҡж ҮеҮҶзҡ„йҷҗеҲ¶пјҢдҪҶSiriд»ЈиЎЁдәҶдәәе·ҘжҷәиғҪеҠ©жүӢеңЁж—Ҙеёёз”ЁжҲ·дҪҝз”Ёж–№йқўеҸ–еҫ—зҡ„йҮҚеӨ§иҝӣжӯҘгҖӮеҫ®иҪҜзҡ„CortanaгҖҒи°·жӯҢзҡ„Assistantе’Ңдәҡ马йҖҠзҡ„Alexaзҙ§йҡҸе…¶еҗҺпјҢеҗ„иҮӘжҺЁеҠЁдәҶйқўеҗ‘ж¶Ҳиҙ№иҖ…зҡ„еҜ№иҜқејҸдәәе·ҘжҷәиғҪзҡ„еҸ‘еұ•гҖӮ
е°Ҫз®ЎеҸ–еҫ—дәҶиҝҷдәӣиҝӣжӯҘпјҢдҪҶиҝҷдёӘж—¶д»Јзҡ„зі»з»ҹеңЁиҜӯеўғзҗҶи§ЈгҖҒеёёиҜҶжҺЁзҗҶд»ҘеҸҠз”ҹжҲҗзңҹжӯЈиҮӘ然зҡ„еӣһеә”ж–№йқўд»Қ然дёҫжӯҘз»ҙиү°гҖӮе®ғ们жҜ”еҹәдәҺ规еҲҷзҡ„зҘ–е…ҲжӣҙеҠ еӨҚжқӮпјҢдҪҶеңЁеҜ№иҜӯиЁҖе’Ңдё–з•Ңзҡ„зҗҶи§Јж–№йқўд»Қ然еӯҳеңЁж №жң¬жҖ§зҡ„еұҖйҷҗжҖ§гҖӮ
иҝҷз§ҚиҪ¬еҸҳеҫ—зӣҠдәҺеӨҡз§Қеӣ зҙ пјҡи®Ўз®—иғҪеҠӣзҡ„жҸҗеҚҮгҖҒз®—жі•зҡ„ж”№иҝӣпјҢд»ҘеҸҠиҮіе…ійҮҚиҰҒзҡ„пјҢеҸҜз”ЁдәҺеҲҶжһҗиҜӯиЁҖжЁЎејҸзҡ„еӨ§еһӢж–Үжң¬иҜӯж–ҷеә“зҡ„еҮәзҺ°гҖӮзі»з»ҹејҖе§ӢиһҚе…Ҙд»ҘдёӢжҠҖжңҜпјҡ
иҜҚжҖ§ж ҮжіЁпјҡиҜҶеҲ«иҜҚиҜӯзҡ„еҠҹиғҪжҳҜеҗҚиҜҚгҖҒеҠЁиҜҚгҖҒеҪўе®№иҜҚзӯүгҖӮ
е‘ҪеҗҚе®һдҪ“иҜҶеҲ«пјҡжЈҖжөӢе’ҢеҲҶзұ»дё“жңүеҗҚиҜҚпјҲдәәзү©гҖҒз»„з»ҮгҖҒең°зӮ№пјүгҖӮ
жғ…ж„ҹеҲҶжһҗпјҡзЎ®е®ҡж–Үжң¬зҡ„жғ…ж„ҹеҹәи°ғгҖӮ
иҜӯжі•еҲҶжһҗпјҡеҲҶжһҗеҸҘеӯҗз»“жһ„д»ҘиҜҶеҲ«иҜҚиҜӯд№Ӣй—ҙзҡ„иҜӯжі•е…ізі»гҖӮ
дёҖйЎ№жҳҫи‘—зҡ„зӘҒз ҙжқҘиҮӘ IBM зҡ„жІғжЈ®пјҢе®ғеңЁжҷәеҠӣз«һиөӣиҠӮзӣ®гҖҠеҚұйҷ©иҫ№зјҳпјҒгҖӢпјҲJeopardy!пјүдёӯеҮ»иҙҘдәҶдәәзұ»еҶ еҶӣгҖӮ 2011е№ҙгҖӮиҷҪ然дёҘж јжқҘиҜҙпјҢжІғ森并йқһдёҖдёӘеҜ№иҜқзі»з»ҹпјҢдҪҶе®ғеұ•зҺ°еҮәдәҶеүҚжүҖжңӘжңүзҡ„иғҪеҠӣпјҢиғҪеӨҹзҗҶи§ЈиҮӘ然иҜӯиЁҖй—®йўҳгҖҒжҗңзҙўжө·йҮҸзҹҘиҜҶеә“并еҪўжҲҗзӯ”жЎҲвҖ”вҖ”иҝҷдәӣиғҪеҠӣеҜ№дәҺдёӢдёҖд»ЈиҒҠеӨ©жңәеҷЁдәәиҮіе…ійҮҚиҰҒгҖӮ
е•Ҷдёҡеә”з”Ёд№ҹйҡҸд№ӢиҖҢжқҘгҖӮиӢ№жһңзҡ„SiriдәҺ2011е№ҙжҺЁеҮәпјҢе°ҶеҜ№иҜқз•ҢйқўеёҰз»ҷдәҶдё»жөҒж¶Ҳиҙ№иҖ…гҖӮиҷҪ然еҸ—еҲ°еҪ“д»Ҡж ҮеҮҶзҡ„йҷҗеҲ¶пјҢдҪҶSiriд»ЈиЎЁдәҶдәәе·ҘжҷәиғҪеҠ©жүӢеңЁж—Ҙеёёз”ЁжҲ·дҪҝз”Ёж–№йқўеҸ–еҫ—зҡ„йҮҚеӨ§иҝӣжӯҘгҖӮеҫ®иҪҜзҡ„CortanaгҖҒи°·жӯҢзҡ„Assistantе’Ңдәҡ马йҖҠзҡ„Alexaзҙ§йҡҸе…¶еҗҺпјҢеҗ„иҮӘжҺЁеҠЁдәҶйқўеҗ‘ж¶Ҳиҙ№иҖ…зҡ„еҜ№иҜқејҸдәәе·ҘжҷәиғҪзҡ„еҸ‘еұ•гҖӮ
е°Ҫз®ЎеҸ–еҫ—дәҶиҝҷдәӣиҝӣжӯҘпјҢдҪҶиҝҷдёӘж—¶д»Јзҡ„зі»з»ҹеңЁиҜӯеўғзҗҶи§ЈгҖҒеёёиҜҶжҺЁзҗҶд»ҘеҸҠз”ҹжҲҗзңҹжӯЈиҮӘ然зҡ„еӣһеә”ж–№йқўд»Қ然дёҫжӯҘз»ҙиү°гҖӮе®ғ们жҜ”еҹәдәҺ规еҲҷзҡ„зҘ–е…ҲжӣҙеҠ еӨҚжқӮпјҢдҪҶеңЁеҜ№иҜӯиЁҖе’Ңдё–з•Ңзҡ„зҗҶи§Јж–№йқўд»Қ然еӯҳеңЁж №жң¬жҖ§зҡ„еұҖйҷҗжҖ§гҖӮ
жңәеҷЁеӯҰд№ е’Ңж•°жҚ®й©ұеҠЁж–№жі•
2010 е№ҙд»ЈдёӯжңҹпјҢйҡҸзқҖжңәеҷЁеӯҰд№ жҠҖжңҜзҡ„дё»жөҒеә”з”ЁпјҢеҜ№иҜқејҸдәәе·ҘжҷәиғҪиҝҺжқҘдәҶеҸҲдёҖж¬ЎиҢғејҸиҪ¬еҸҳгҖӮе·ҘзЁӢеёҲ们дёҚеҶҚдҫқиө–жүӢе·ҘеҲ¶е®ҡзҡ„规еҲҷжҲ–жңүйҷҗзҡ„з»ҹи®ЎжЁЎеһӢпјҢиҖҢжҳҜејҖе§Ӣжһ„е»әиғҪеӨҹзӣҙжҺҘд»Һжө·йҮҸж•°жҚ®дёӯеӯҰд№ жЁЎејҸзҡ„зі»з»ҹгҖӮ
иҝҷдёӘж—¶д»Ји§ҒиҜҒдәҶж„ҸеӣҫеҲҶзұ»е’Ңе®һдҪ“жҸҗеҸ–дҪңдёәеҜ№иҜқејҸжһ¶жһ„ж ёеҝғз»„жҲҗйғЁеҲҶзҡ„е…ҙиө·гҖӮеҪ“з”ЁжҲ·еҸ‘еҮәиҜ·жұӮж—¶пјҢзі»з»ҹдјҡпјҡ
еҜ№ж•ҙдҪ“ж„ҸеӣҫиҝӣиЎҢеҲҶзұ»пјҲдҫӢеҰӮпјҢйў„и®ўиҲӘзҸӯгҖҒжҹҘзңӢеӨ©ж°”гҖҒж’ӯж”ҫйҹід№җпјү
жҸҗеҸ–зӣёе…іе®һдҪ“пјҲдҫӢеҰӮпјҢдҪҚзҪ®гҖҒж—ҘжңҹгҖҒжӯҢжӣІеҗҚз§°пјү
е°Ҷиҝҷдәӣе®һдҪ“жҳ е°„еҲ°зү№е®ҡзҡ„ж“ҚдҪңжҲ–е“Қеә”
FacebookпјҲзҺ°дёә MetaпјүдәҺ 2016 е№ҙжҺЁеҮәзҡ„ Messenger е№іеҸ°пјҢи®©ејҖеҸ‘иҖ…иғҪеӨҹеҲӣе»әиғҪеӨҹиҰҶзӣ–ж•°зҷҫдёҮз”ЁжҲ·зҡ„иҒҠеӨ©жңәеҷЁдәәпјҢеј•еҸ‘дәҶдёҖжіўе•ҶдёҡзғӯжҪ®гҖӮи®ёеӨҡдјҒдёҡдәүзӣёйғЁзҪІиҒҠеӨ©жңәеҷЁдәәпјҢдҪҶз»“жһңеҘҪеқҸеҸӮеҚҠгҖӮж—©жңҹзҡ„е•ҶдёҡеҢ–е®һж–Ҫеёёеёёеӣ зҗҶи§Јжңүйҷҗе’ҢеҜ№иҜқжөҒзЁӢеғөеҢ–иҖҢд»Өз”ЁжҲ·ж„ҹеҲ°жІ®дё§гҖӮ
еҜ№иҜқејҸзі»з»ҹзҡ„жҠҖжңҜжһ¶жһ„д№ҹеңЁжӯӨжңҹй—ҙдёҚж–ӯеҸ‘еұ•гҖӮе…ёеһӢзҡ„ж–№жі•ж¶үеҸҠдёҖзі»еҲ—专用组件зҡ„жөҒж°ҙзәҝпјҡ
иҮӘеҠЁиҜӯйҹіиҜҶеҲ«пјҲз”ЁдәҺиҜӯйҹіз•Ңйқўпјү
иҮӘ然иҜӯиЁҖзҗҶи§Ј
еҜ№иҜқз®ЎзҗҶ
иҮӘ然иҜӯиЁҖз”ҹжҲҗ
ж–Үжң¬иҪ¬иҜӯйҹіпјҲз”ЁдәҺиҜӯйҹіз•Ңйқўпјү
жҜҸдёӘ组件йғҪеҸҜд»ҘеҚ•зӢ¬дјҳеҢ–пјҢд»ҺиҖҢе®һзҺ°жёҗиҝӣејҸж”№иҝӣгҖӮ然иҖҢпјҢиҝҷдәӣжөҒж°ҙзәҝжһ¶жһ„жңүж—¶дјҡеҸ—еҲ°й”ҷиҜҜдј ж’ӯзҡ„еҪұе“ҚвҖ”вҖ”ж—©жңҹйҳ¶ж®өзҡ„й”ҷиҜҜдјҡеңЁж•ҙдёӘзі»з»ҹдёӯдә§з”ҹиҝһй”ҒеҸҚеә”гҖӮ
иҷҪ然жңәеҷЁеӯҰд№ жҳҫи‘—жҸҗеҚҮдәҶзі»з»ҹзҡ„иғҪеҠӣпјҢдҪҶзі»з»ҹд»Қ然йҡҫд»ҘеңЁй•ҝж—¶й—ҙеҜ№иҜқдёӯдҝқжҢҒиҜӯеўғгҖҒзҗҶи§Јйҡҗеҗ«дҝЎжҒҜд»ҘеҸҠз”ҹжҲҗзңҹжӯЈеӨҡж ·еҢ–е’ҢиҮӘ然зҡ„е“Қеә”гҖӮдёӢдёҖдёӘзӘҒз ҙйңҖиҰҒдёҖз§ҚжӣҙеҪ»еә•зҡ„ж–№жі•гҖӮ
иҝҷдёӘж—¶д»Ји§ҒиҜҒдәҶж„ҸеӣҫеҲҶзұ»е’Ңе®һдҪ“жҸҗеҸ–дҪңдёәеҜ№иҜқејҸжһ¶жһ„ж ёеҝғз»„жҲҗйғЁеҲҶзҡ„е…ҙиө·гҖӮеҪ“з”ЁжҲ·еҸ‘еҮәиҜ·жұӮж—¶пјҢзі»з»ҹдјҡпјҡ
еҜ№ж•ҙдҪ“ж„ҸеӣҫиҝӣиЎҢеҲҶзұ»пјҲдҫӢеҰӮпјҢйў„и®ўиҲӘзҸӯгҖҒжҹҘзңӢеӨ©ж°”гҖҒж’ӯж”ҫйҹід№җпјү
жҸҗеҸ–зӣёе…іе®һдҪ“пјҲдҫӢеҰӮпјҢдҪҚзҪ®гҖҒж—ҘжңҹгҖҒжӯҢжӣІеҗҚз§°пјү
е°Ҷиҝҷдәӣе®һдҪ“жҳ е°„еҲ°зү№е®ҡзҡ„ж“ҚдҪңжҲ–е“Қеә”
FacebookпјҲзҺ°дёә MetaпјүдәҺ 2016 е№ҙжҺЁеҮәзҡ„ Messenger е№іеҸ°пјҢи®©ејҖеҸ‘иҖ…иғҪеӨҹеҲӣе»әиғҪеӨҹиҰҶзӣ–ж•°зҷҫдёҮз”ЁжҲ·зҡ„иҒҠеӨ©жңәеҷЁдәәпјҢеј•еҸ‘дәҶдёҖжіўе•ҶдёҡзғӯжҪ®гҖӮи®ёеӨҡдјҒдёҡдәүзӣёйғЁзҪІиҒҠеӨ©жңәеҷЁдәәпјҢдҪҶз»“жһңеҘҪеқҸеҸӮеҚҠгҖӮж—©жңҹзҡ„е•ҶдёҡеҢ–е®һж–Ҫеёёеёёеӣ зҗҶи§Јжңүйҷҗе’ҢеҜ№иҜқжөҒзЁӢеғөеҢ–иҖҢд»Өз”ЁжҲ·ж„ҹеҲ°жІ®дё§гҖӮ
еҜ№иҜқејҸзі»з»ҹзҡ„жҠҖжңҜжһ¶жһ„д№ҹеңЁжӯӨжңҹй—ҙдёҚж–ӯеҸ‘еұ•гҖӮе…ёеһӢзҡ„ж–№жі•ж¶үеҸҠдёҖзі»еҲ—专用组件зҡ„жөҒж°ҙзәҝпјҡ
иҮӘеҠЁиҜӯйҹіиҜҶеҲ«пјҲз”ЁдәҺиҜӯйҹіз•Ңйқўпјү
иҮӘ然иҜӯиЁҖзҗҶи§Ј
еҜ№иҜқз®ЎзҗҶ
иҮӘ然иҜӯиЁҖз”ҹжҲҗ
ж–Үжң¬иҪ¬иҜӯйҹіпјҲз”ЁдәҺиҜӯйҹіз•Ңйқўпјү
жҜҸдёӘ组件йғҪеҸҜд»ҘеҚ•зӢ¬дјҳеҢ–пјҢд»ҺиҖҢе®һзҺ°жёҗиҝӣејҸж”№иҝӣгҖӮ然иҖҢпјҢиҝҷдәӣжөҒж°ҙзәҝжһ¶жһ„жңүж—¶дјҡеҸ—еҲ°й”ҷиҜҜдј ж’ӯзҡ„еҪұе“ҚвҖ”вҖ”ж—©жңҹйҳ¶ж®өзҡ„й”ҷиҜҜдјҡеңЁж•ҙдёӘзі»з»ҹдёӯдә§з”ҹиҝһй”ҒеҸҚеә”гҖӮ
иҷҪ然жңәеҷЁеӯҰд№ жҳҫи‘—жҸҗеҚҮдәҶзі»з»ҹзҡ„иғҪеҠӣпјҢдҪҶзі»з»ҹд»Қ然йҡҫд»ҘеңЁй•ҝж—¶й—ҙеҜ№иҜқдёӯдҝқжҢҒиҜӯеўғгҖҒзҗҶи§Јйҡҗеҗ«дҝЎжҒҜд»ҘеҸҠз”ҹжҲҗзңҹжӯЈеӨҡж ·еҢ–е’ҢиҮӘ然зҡ„е“Қеә”гҖӮдёӢдёҖдёӘзӘҒз ҙйңҖиҰҒдёҖз§ҚжӣҙеҪ»еә•зҡ„ж–№жі•гҖӮ
Transformer йқ©е‘ҪпјҡзҘһз»ҸиҜӯиЁҖжЁЎеһӢ
2017е№ҙжҳҜдәәе·ҘжҷәиғҪеҺҶеҸІдёҠзҡ„дёҖдёӘеҲҶж°ҙеІӯпјҢгҖҠжіЁж„ҸеҠӣе°ұжҳҜдёҖеҲҮгҖӢдёҖд№Ұзҡ„еҸ‘иЎЁпјҢиҜҘд№Ұд»Ӣз»ҚдәҶеҪ»еә•ж”№еҸҳиҮӘ然иҜӯиЁҖеӨ„зҗҶзҡ„Transformerжһ¶жһ„гҖӮдёҺд»ҘеҫҖжҢүйЎәеәҸеӨ„зҗҶж–Үжң¬зҡ„ж–№жі•дёҚеҗҢпјҢTransformerеҸҜд»ҘеҗҢж—¶еӨ„зҗҶж•ҙзҜҮж–Үз« пјҢд»ҺиҖҢиғҪеӨҹжӣҙеҘҪең°жҚ•жҚүеҚ•иҜҚд№Ӣй—ҙзҡ„е…ізі»пјҢж— и®әе®ғ们д№Ӣй—ҙзҡ„и·қзҰ»иҝңиҝ‘гҖӮ
иҝҷйЎ№еҲӣж–°жҺЁеҠЁдәҶж—ҘзӣҠејәеӨ§зҡ„иҜӯиЁҖжЁЎеһӢзҡ„ејҖеҸ‘гҖӮ2018е№ҙпјҢи°·жӯҢжҺЁеҮәдәҶBERTпјҲеҹәдәҺTransformerзҡ„еҸҢеҗ‘зј–з ҒеҷЁиЎЁзӨәпјүпјҢжҳҫи‘—жҸҗеҚҮдәҶе®ғеңЁеҗ„з§ҚиҜӯиЁҖзҗҶи§Јд»»еҠЎдёҠзҡ„иЎЁзҺ°гҖӮ2019е№ҙпјҢOpenAIеҸ‘еёғдәҶGPT-2пјҢеұ•зҺ°дәҶе…¶еңЁз”ҹжҲҗиҝһиҙҜгҖҒдёҠдёӢж–Үзӣёе…ізҡ„ж–Үжң¬ж–№йқўеүҚжүҖжңӘжңүзҡ„иғҪеҠӣгҖӮ
жңҖжҳҫи‘—зҡ„йЈһи·ғеҸ‘з”ҹеңЁ2020е№ҙпјҢGPT-3е®һзҺ°дәҶзӘҒз ҙпјҢе…¶еҸӮж•°ж•°йҮҸй«ҳиҫҫ1750дәҝдёӘпјҲиҖҢGPT-2еҸӘжңү15дәҝдёӘпјүгҖӮ规模зҡ„еӨ§е№…жҸҗеҚҮпјҢеҠ дёҠжһ¶жһ„зҡ„ж”№иҝӣпјҢеёҰжқҘдәҶиҙЁзҡ„йЈһи·ғгҖӮ GPT-3 еҸҜд»Ҙз”ҹжҲҗйқһеёёжҺҘиҝ‘дәәзұ»зҡ„ж–Үжң¬пјҢзҗҶи§Јж•°еҚғдёӘеҚ•иҜҚзҡ„дёҠдёӢж–ҮпјҢз”ҡиҮіиғҪеӨҹжү§иЎҢжңӘз»ҸжҳҺзЎ®и®ӯз»ғзҡ„д»»еҠЎгҖӮ
еҜ№дәҺеҜ№иҜқејҸдәәе·ҘжҷәиғҪиҖҢиЁҖпјҢиҝҷдәӣиҝӣжӯҘиҪ¬еҢ–дёәиҒҠеӨ©жңәеҷЁдәәпјҢе®ғ们иғҪеӨҹпјҡ
еңЁеӨҡиҪ®еҜ№иҜқдёӯдҝқжҢҒиҝһиҙҜзҡ„еҜ№иҜқ
ж— йңҖжҳҺзЎ®и®ӯз»ғеҚіеҸҜзҗҶи§Јз»Ҷеҫ®зҡ„з–‘й—®
з”ҹжҲҗеӨҡж ·еҢ–дё”з¬ҰеҗҲиҜӯеўғзҡ„еӣһеә”
и°ғж•ҙиҜӯж°”е’ҢйЈҺж јд»ҘйҖӮеә”з”ЁжҲ·
еӨ„зҗҶжӯ§д№ү并еңЁеҝ…иҰҒж—¶иҝӣиЎҢжҫ„жё…
ChatGPT дәҺ 2022 е№ҙеә•еҸ‘еёғпјҢе°ҶиҝҷдәӣеҠҹиғҪжҺЁеҗ‘дё»жөҒпјҢеңЁеҸ‘еёғеҮ еӨ©еҶ…е°ұеҗёеј•дәҶи¶…иҝҮдёҖзҷҫдёҮз”ЁжҲ·гҖӮзӘҒ然д№Ӣй—ҙпјҢжҷ®йҖҡеӨ§дј—иғҪеӨҹжҺҘи§ҰеҲ°еҜ№иҜқејҸдәәе·ҘжҷәиғҪпјҢе®ғдјјд№ҺдёҺд»ҘеҫҖд»»дҪ•дәәе·ҘжҷәиғҪйғҪжҲӘ然дёҚеҗҢвҖ”вҖ”жӣҙеҠ зҒөжҙ»гҖҒзҹҘиҜҶжӣҙжёҠеҚҡгҖҒдәӨдә’жӣҙиҮӘ然гҖӮ
е•Ҷдёҡеә”з”Ёд№ҹйҡҸд№Ӣиҝ…йҖҹеҸ‘еұ•пјҢи®ёеӨҡе…¬еҸёе°ҶеӨ§еһӢиҜӯиЁҖжЁЎеһӢиһҚе…ҘеҲ°д»–们зҡ„е®ўжҲ·жңҚеҠЎе№іеҸ°гҖҒеҶ…е®№еҲӣе»әе·Ҙе…·е’Ңз”ҹдә§еҠӣеә”з”ЁзЁӢеәҸдёӯгҖӮеҝ«йҖҹйҮҮз”ЁеҸҚжҳ дәҶжҠҖжңҜйЈһи·ғе’ҢиҝҷдәӣжЁЎеһӢжҸҗдҫӣзҡ„зӣҙи§Ӯз•ҢйқўвҖ”вҖ”жҜ•з«ҹпјҢеҜ№иҜқжҳҜдәәзұ»дәӨжөҒжңҖиҮӘ然зҡ„ж–№ејҸгҖӮ
иҝҷйЎ№еҲӣж–°жҺЁеҠЁдәҶж—ҘзӣҠејәеӨ§зҡ„иҜӯиЁҖжЁЎеһӢзҡ„ејҖеҸ‘гҖӮ2018е№ҙпјҢи°·жӯҢжҺЁеҮәдәҶBERTпјҲеҹәдәҺTransformerзҡ„еҸҢеҗ‘зј–з ҒеҷЁиЎЁзӨәпјүпјҢжҳҫи‘—жҸҗеҚҮдәҶе®ғеңЁеҗ„з§ҚиҜӯиЁҖзҗҶи§Јд»»еҠЎдёҠзҡ„иЎЁзҺ°гҖӮ2019е№ҙпјҢOpenAIеҸ‘еёғдәҶGPT-2пјҢеұ•зҺ°дәҶе…¶еңЁз”ҹжҲҗиҝһиҙҜгҖҒдёҠдёӢж–Үзӣёе…ізҡ„ж–Үжң¬ж–№йқўеүҚжүҖжңӘжңүзҡ„иғҪеҠӣгҖӮ
жңҖжҳҫи‘—зҡ„йЈһи·ғеҸ‘з”ҹеңЁ2020е№ҙпјҢGPT-3е®һзҺ°дәҶзӘҒз ҙпјҢе…¶еҸӮж•°ж•°йҮҸй«ҳиҫҫ1750дәҝдёӘпјҲиҖҢGPT-2еҸӘжңү15дәҝдёӘпјүгҖӮ规模зҡ„еӨ§е№…жҸҗеҚҮпјҢеҠ дёҠжһ¶жһ„зҡ„ж”№иҝӣпјҢеёҰжқҘдәҶиҙЁзҡ„йЈһи·ғгҖӮ GPT-3 еҸҜд»Ҙз”ҹжҲҗйқһеёёжҺҘиҝ‘дәәзұ»зҡ„ж–Үжң¬пјҢзҗҶи§Јж•°еҚғдёӘеҚ•иҜҚзҡ„дёҠдёӢж–ҮпјҢз”ҡиҮіиғҪеӨҹжү§иЎҢжңӘз»ҸжҳҺзЎ®и®ӯз»ғзҡ„д»»еҠЎгҖӮ
еҜ№дәҺеҜ№иҜқејҸдәәе·ҘжҷәиғҪиҖҢиЁҖпјҢиҝҷдәӣиҝӣжӯҘиҪ¬еҢ–дёәиҒҠеӨ©жңәеҷЁдәәпјҢе®ғ们иғҪеӨҹпјҡ
еңЁеӨҡиҪ®еҜ№иҜқдёӯдҝқжҢҒиҝһиҙҜзҡ„еҜ№иҜқ
ж— йңҖжҳҺзЎ®и®ӯз»ғеҚіеҸҜзҗҶи§Јз»Ҷеҫ®зҡ„з–‘й—®
з”ҹжҲҗеӨҡж ·еҢ–дё”з¬ҰеҗҲиҜӯеўғзҡ„еӣһеә”
и°ғж•ҙиҜӯж°”е’ҢйЈҺж јд»ҘйҖӮеә”з”ЁжҲ·
еӨ„зҗҶжӯ§д№ү并еңЁеҝ…иҰҒж—¶иҝӣиЎҢжҫ„жё…
ChatGPT дәҺ 2022 е№ҙеә•еҸ‘еёғпјҢе°ҶиҝҷдәӣеҠҹиғҪжҺЁеҗ‘дё»жөҒпјҢеңЁеҸ‘еёғеҮ еӨ©еҶ…е°ұеҗёеј•дәҶи¶…иҝҮдёҖзҷҫдёҮз”ЁжҲ·гҖӮзӘҒ然д№Ӣй—ҙпјҢжҷ®йҖҡеӨ§дј—иғҪеӨҹжҺҘи§ҰеҲ°еҜ№иҜқејҸдәәе·ҘжҷәиғҪпјҢе®ғдјјд№ҺдёҺд»ҘеҫҖд»»дҪ•дәәе·ҘжҷәиғҪйғҪжҲӘ然дёҚеҗҢвҖ”вҖ”жӣҙеҠ зҒөжҙ»гҖҒзҹҘиҜҶжӣҙжёҠеҚҡгҖҒдәӨдә’жӣҙиҮӘ然гҖӮ
е•Ҷдёҡеә”з”Ёд№ҹйҡҸд№Ӣиҝ…йҖҹеҸ‘еұ•пјҢи®ёеӨҡе…¬еҸёе°ҶеӨ§еһӢиҜӯиЁҖжЁЎеһӢиһҚе…ҘеҲ°д»–们зҡ„е®ўжҲ·жңҚеҠЎе№іеҸ°гҖҒеҶ…е®№еҲӣе»әе·Ҙе…·е’Ңз”ҹдә§еҠӣеә”з”ЁзЁӢеәҸдёӯгҖӮеҝ«йҖҹйҮҮз”ЁеҸҚжҳ дәҶжҠҖжңҜйЈһи·ғе’ҢиҝҷдәӣжЁЎеһӢжҸҗдҫӣзҡ„зӣҙи§Ӯз•ҢйқўвҖ”вҖ”жҜ•з«ҹпјҢеҜ№иҜқжҳҜдәәзұ»дәӨжөҒжңҖиҮӘ然зҡ„ж–№ејҸгҖӮ
жөӢиҜ•жӮЁзҡ„дёҡеҠЎ еҲҶй’ҹ
еҲӣе»әжӮЁзҡ„иҙҰжҲ·е№¶еңЁеҮ еҲҶй’ҹеҶ…еҗҜеҠЁжӮЁзҡ„AIиҒҠеӨ©жңәеҷЁдәәгҖӮе®Ңе…ЁеҸҜе®ҡеҲ¶пјҢж— йңҖзј–з Ғ - з«ӢеҚіејҖе§Ӣеҗёеј•жӮЁзҡ„е®ўжҲ·пјҒ
еҮ еҲҶй’ҹеҚіеҸҜе°ұз»Ә
ж— йңҖзј–з Ғ
еӨҡжЁЎејҸеҠҹиғҪпјҡи¶…и¶ҠзәҜж–Үжң¬еҜ№иҜқ
иҷҪ然ж–Үжң¬дёҖзӣҙжҳҜеҜ№иҜқејҸдәәе·ҘжҷәиғҪеҸ‘еұ•зҡ„дё»еҜјпјҢдҪҶиҝ‘е№ҙжқҘпјҢдәә们ејҖе§Ӣеҗ‘иғҪеӨҹзҗҶи§Је’Ңз”ҹжҲҗеӨҡз§ҚеӘ’дҪ“зұ»еһӢзҡ„еӨҡжЁЎжҖҒзі»з»ҹиҝҲиҝӣгҖӮиҝҷз§Қжј”еҸҳеҸҚжҳ дәҶдәәзұ»жІҹйҖҡзҡ„дёҖдёӘеҹәжң¬зңҹзҗҶвҖ”вҖ”жҲ‘们дёҚд»…д»…дҪҝз”Ёж–Үеӯ—пјӣжҲ‘们иҝҳйҖҡиҝҮжүӢеҠҝгҖҒеұ•зӨәеӣҫеғҸгҖҒз»ҳеҲ¶еӣҫиЎЁд»ҘеҸҠеҲ©з”ЁзҺҜеўғжқҘдј иҫҫж„Ҹд№үгҖӮ
еғҸ DALL-EгҖҒMidjourney е’Ң Stable Diffusion иҝҷж ·зҡ„и§Ҷи§үиҜӯиЁҖжЁЎеһӢеұ•зӨәдәҶж №жҚ®ж–Үжң¬жҸҸиҝ°з”ҹжҲҗеӣҫеғҸзҡ„иғҪеҠӣпјҢиҖҢеғҸ GPT-4 иҝҷж ·е…·еӨҮи§Ҷи§үеҠҹиғҪзҡ„жЁЎеһӢеҲҷеҸҜд»ҘеҲҶжһҗеӣҫеғҸ并иҝӣиЎҢжҷәиғҪи®Ёи®әгҖӮиҝҷдёәеҜ№иҜқејҸз•ҢйқўејҖиҫҹдәҶж–°зҡ„еҸҜиғҪжҖ§пјҡ
иғҪеӨҹеҲҶжһҗеҸ—жҚҹе•Ҷе“Ғз…§зүҮзҡ„е®ўжңҚжңәеҷЁдәә
иғҪеӨҹйҖҡиҝҮеӣҫзүҮиҜҶеҲ«е•Ҷе“Ғ并жҹҘжүҫзұ»дјје•Ҷе“Ғзҡ„иҙӯзү©еҠ©жүӢ
иғҪеӨҹи§ЈйҮҠеӣҫиЎЁе’Ңи§Ҷи§үжҰӮеҝөзҡ„ж•ҷиӮІе·Ҙе…·
иғҪеӨҹдёәи§Ҷйҡңз”ЁжҲ·жҸҸиҝ°еӣҫеғҸзҡ„иҫ…еҠ©еҠҹиғҪ
иҜӯйҹіеҠҹиғҪд№ҹеҸ–еҫ—дәҶжҳҫи‘—иҝӣжӯҘгҖӮж—©жңҹзҡ„иҜӯйҹіз•ҢйқўпјҢдҫӢеҰӮ IVRпјҲдәӨдә’ејҸиҜӯйҹіеә”зӯ”пјүзі»з»ҹпјҢз”ұдәҺеұҖйҷҗдәҺеғөзЎ¬зҡ„е‘Ҫд»Өе’ҢиҸңеҚ•з»“жһ„пјҢд»Ҙд»ӨдәәжІ®дё§иҖҢи‘—з§°гҖӮзҺ°д»ЈиҜӯйҹіеҠ©жүӢиғҪеӨҹзҗҶи§ЈиҮӘ然зҡ„иҜӯйҹіжЁЎејҸпјҢеӨ„зҗҶдёҚеҗҢзҡ„еҸЈйҹіе’ҢиЁҖиҜӯйҡңзўҚпјҢ并д»Ҙи¶ҠжқҘи¶ҠиҮӘ然зҡ„еҗҲжҲҗиҜӯйҹіеҒҡеҮәеӣһеә”гҖӮ
иҝҷдәӣеҠҹиғҪзҡ„иһҚеҗҲжӯЈеңЁеҲӣйҖ зңҹжӯЈзҡ„еӨҡжЁЎжҖҒеҜ№иҜқејҸдәәе·ҘжҷәиғҪпјҢе®ғеҸҜд»Ҙж №жҚ®жғ…еўғе’Ңз”ЁжҲ·йңҖжұӮеңЁдёҚеҗҢжІҹйҖҡжЁЎејҸд№Ӣй—ҙж— зјқеҲҮжҚўгҖӮз”ЁжҲ·еҸҜиғҪдјҡе…ҲйҖҡиҝҮж–Үжң¬иҜўй—®еҰӮдҪ•дҝ®зҗҶжү“еҚ°жңәпјҢ然еҗҺеҸ‘йҖҒй”ҷиҜҜдҝЎжҒҜзҡ„з…§зүҮпјҢжҺҘ收зӘҒеҮәжҳҫзӨәзӣёе…іжҢүй’®зҡ„еӣҫиЎЁпјҢ然еҗҺеңЁеҝҷдәҺз»ҙдҝ®ж—¶еҲҮжҚўеҲ°иҜӯйҹіжҢҮд»ӨгҖӮ
иҝҷз§ҚеӨҡжЁЎжҖҒж–№жі•дёҚд»…д»ЈиЎЁдәҶжҠҖжңҜиҝӣжӯҘпјҢд№ҹд»ЈиЎЁдәҶеҗ‘жӣҙиҮӘ然зҡ„дәәжңәдәӨдә’зҡ„ж №жң¬иҪ¬еҸҳвҖ”вҖ”д»ҘжңҖйҖӮеҗҲз”ЁжҲ·еҪ“еүҚжғ…еўғе’ҢйңҖжұӮзҡ„жІҹйҖҡжЁЎејҸжқҘж»Ўи¶із”ЁжҲ·зҡ„йңҖжұӮгҖӮ
еғҸ DALL-EгҖҒMidjourney е’Ң Stable Diffusion иҝҷж ·зҡ„и§Ҷи§үиҜӯиЁҖжЁЎеһӢеұ•зӨәдәҶж №жҚ®ж–Үжң¬жҸҸиҝ°з”ҹжҲҗеӣҫеғҸзҡ„иғҪеҠӣпјҢиҖҢеғҸ GPT-4 иҝҷж ·е…·еӨҮи§Ҷи§үеҠҹиғҪзҡ„жЁЎеһӢеҲҷеҸҜд»ҘеҲҶжһҗеӣҫеғҸ并иҝӣиЎҢжҷәиғҪи®Ёи®әгҖӮиҝҷдёәеҜ№иҜқејҸз•ҢйқўејҖиҫҹдәҶж–°зҡ„еҸҜиғҪжҖ§пјҡ
иғҪеӨҹеҲҶжһҗеҸ—жҚҹе•Ҷе“Ғз…§зүҮзҡ„е®ўжңҚжңәеҷЁдәә
иғҪеӨҹйҖҡиҝҮеӣҫзүҮиҜҶеҲ«е•Ҷе“Ғ并жҹҘжүҫзұ»дјје•Ҷе“Ғзҡ„иҙӯзү©еҠ©жүӢ
иғҪеӨҹи§ЈйҮҠеӣҫиЎЁе’Ңи§Ҷи§үжҰӮеҝөзҡ„ж•ҷиӮІе·Ҙе…·
иғҪеӨҹдёәи§Ҷйҡңз”ЁжҲ·жҸҸиҝ°еӣҫеғҸзҡ„иҫ…еҠ©еҠҹиғҪ
иҜӯйҹіеҠҹиғҪд№ҹеҸ–еҫ—дәҶжҳҫи‘—иҝӣжӯҘгҖӮж—©жңҹзҡ„иҜӯйҹіз•ҢйқўпјҢдҫӢеҰӮ IVRпјҲдәӨдә’ејҸиҜӯйҹіеә”зӯ”пјүзі»з»ҹпјҢз”ұдәҺеұҖйҷҗдәҺеғөзЎ¬зҡ„е‘Ҫд»Өе’ҢиҸңеҚ•з»“жһ„пјҢд»Ҙд»ӨдәәжІ®дё§иҖҢи‘—з§°гҖӮзҺ°д»ЈиҜӯйҹіеҠ©жүӢиғҪеӨҹзҗҶи§ЈиҮӘ然зҡ„иҜӯйҹіжЁЎејҸпјҢеӨ„зҗҶдёҚеҗҢзҡ„еҸЈйҹіе’ҢиЁҖиҜӯйҡңзўҚпјҢ并д»Ҙи¶ҠжқҘи¶ҠиҮӘ然зҡ„еҗҲжҲҗиҜӯйҹіеҒҡеҮәеӣһеә”гҖӮ
иҝҷдәӣеҠҹиғҪзҡ„иһҚеҗҲжӯЈеңЁеҲӣйҖ зңҹжӯЈзҡ„еӨҡжЁЎжҖҒеҜ№иҜқејҸдәәе·ҘжҷәиғҪпјҢе®ғеҸҜд»Ҙж №жҚ®жғ…еўғе’Ңз”ЁжҲ·йңҖжұӮеңЁдёҚеҗҢжІҹйҖҡжЁЎејҸд№Ӣй—ҙж— зјқеҲҮжҚўгҖӮз”ЁжҲ·еҸҜиғҪдјҡе…ҲйҖҡиҝҮж–Үжң¬иҜўй—®еҰӮдҪ•дҝ®зҗҶжү“еҚ°жңәпјҢ然еҗҺеҸ‘йҖҒй”ҷиҜҜдҝЎжҒҜзҡ„з…§зүҮпјҢжҺҘ收зӘҒеҮәжҳҫзӨәзӣёе…іжҢүй’®зҡ„еӣҫиЎЁпјҢ然еҗҺеңЁеҝҷдәҺз»ҙдҝ®ж—¶еҲҮжҚўеҲ°иҜӯйҹіжҢҮд»ӨгҖӮ
иҝҷз§ҚеӨҡжЁЎжҖҒж–№жі•дёҚд»…д»ЈиЎЁдәҶжҠҖжңҜиҝӣжӯҘпјҢд№ҹд»ЈиЎЁдәҶеҗ‘жӣҙиҮӘ然зҡ„дәәжңәдәӨдә’зҡ„ж №жң¬иҪ¬еҸҳвҖ”вҖ”д»ҘжңҖйҖӮеҗҲз”ЁжҲ·еҪ“еүҚжғ…еўғе’ҢйңҖжұӮзҡ„жІҹйҖҡжЁЎејҸжқҘж»Ўи¶із”ЁжҲ·зҡ„йңҖжұӮгҖӮ
жЈҖзҙўеўһејәз”ҹжҲҗпјҡд»ҘдәӢе®һдёәеҹәзЎҖзҡ„дәәе·ҘжҷәиғҪ
е°Ҫз®ЎеӨ§еһӢиҜӯиЁҖжЁЎеһӢжӢҘжңүд»ӨдәәеҚ°иұЎж·ұеҲ»зҡ„иғҪеҠӣпјҢдҪҶе®ғ们д№ҹеӯҳеңЁеӣәжңүзҡ„еұҖйҷҗжҖ§гҖӮе®ғ们дјҡвҖңе№»еҢ–вҖқдҝЎжҒҜпјҢиҮӘдҝЎең°йҷҲиҝ°зңӢдјјеҗҲзҗҶдҪҶеҚҙдёҚжӯЈзЎ®зҡ„дәӢе®һгҖӮе®ғ们зҡ„зҹҘиҜҶд»…йҷҗдәҺи®ӯз»ғж•°жҚ®пјҢд»ҺиҖҢйҖ жҲҗдәҶзҹҘиҜҶзҡ„жҲӘжӯўж—ҘжңҹгҖӮиҖҢдё”пјҢйҷӨйқһз»ҸиҝҮдё“й—Ёи®ҫи®ЎпјҢеҗҰеҲҷе®ғд»¬ж— жі•и®ҝй—®е®һж—¶дҝЎжҒҜжҲ–дё“з”Ёж•°жҚ®еә“гҖӮ
жЈҖзҙўеўһејәз”ҹжҲҗ (RAG) еә”иҝҗиҖҢз”ҹпјҢж—ЁеңЁи§ЈеҶіиҝҷдәӣжҢ‘жҲҳгҖӮRAG зі»з»ҹ并йқһд»…д»…дҫқиө–дәҺи®ӯз»ғиҝҮзЁӢдёӯеӯҰд№ еҲ°зҡ„еҸӮж•°пјҢиҖҢжҳҜе°ҶиҜӯиЁҖжЁЎеһӢзҡ„з”ҹжҲҗиғҪеҠӣдёҺеҸҜд»Ҙи®ҝй—®еӨ–йғЁзҹҘиҜҶжәҗзҡ„жЈҖзҙўжңәеҲ¶зӣёз»“еҗҲгҖӮ
е…ёеһӢзҡ„ RAG жһ¶жһ„е·ҘдҪңеҺҹзҗҶеҰӮдёӢпјҡ
зі»з»ҹжҺҘ收用жҲ·жҹҘиҜў
зі»з»ҹеңЁзӣёе…ізҹҘиҜҶеә“дёӯжҗңзҙўдёҺжҹҘиҜўзӣёе…ізҡ„дҝЎжҒҜ
зі»з»ҹе°ҶжҹҘиҜўе’ҢжЈҖзҙўеҲ°зҡ„дҝЎжҒҜиҫ“е…ҘиҜӯиЁҖжЁЎеһӢ
жЁЎеһӢж №жҚ®жЈҖзҙўеҲ°зҡ„дәӢе®һз”ҹжҲҗе“Қеә”
иҝҷз§Қж–№жі•е…·жңүд»ҘдёӢдјҳеҠҝпјҡ
еҹәдәҺз»ҸиҝҮйӘҢиҜҒзҡ„дҝЎжҒҜз”ҹжҲҗе“Қеә”пјҢд»ҺиҖҢиҺ·еҫ—жӣҙеҮҶзЎ®гҖҒжӣҙз¬ҰеҗҲдәӢе®һзҡ„е“Қеә”
иғҪеӨҹи®ҝй—®жЁЎеһӢи®ӯз»ғжҲӘжӯўеҖјд»ҘеӨ–зҡ„жңҖж–°дҝЎжҒҜ
д»Һе…¬еҸёж–ҮжЎЈзӯүзү№е®ҡйўҶеҹҹжқҘжәҗиҺ·еҸ–дё“дёҡзҹҘиҜҶ
йҖҡиҝҮеј•з”ЁдҝЎжҒҜжқҘжәҗе®һзҺ°йҖҸжҳҺеәҰе’ҢеҪ’еӣ
еҜ№дәҺе®һж–ҪеҜ№иҜқејҸ AI зҡ„дјҒдёҡиҖҢиЁҖпјҢRAG еңЁе®ўжҲ·жңҚеҠЎеә”з”Ёдёӯе·Іиў«иҜҒжҳҺе…·жңүзү№еҲ«зҡ„д»·еҖјгҖӮдҫӢеҰӮпјҢ银иЎҢиҒҠеӨ©жңәеҷЁдәәеҸҜд»Ҙи®ҝй—®жңҖж–°зҡ„дҝқеҚ•ж–Ү件гҖҒиҙҰжҲ·дҝЎжҒҜе’ҢдәӨжҳ“и®°еҪ•пјҢд»ҺиҖҢжҸҗдҫӣеҮҶзЎ®гҖҒдёӘжҖ§еҢ–зҡ„е“Қеә”пјҢиҖҢиҝҷеңЁзӢ¬з«Ӣзҡ„иҜӯиЁҖжЁЎеһӢдёӯжҳҜж— жі•е®һзҺ°зҡ„гҖӮ
RAG зі»з»ҹдёҚж–ӯеҸ‘еұ•пјҢжЈҖзҙўеҮҶзЎ®жҖ§дёҚж–ӯжҸҗй«ҳпјҢе°ҶжЈҖзҙўеҲ°зҡ„дҝЎжҒҜдёҺз”ҹжҲҗзҡ„ж–Үжң¬иҝӣиЎҢйӣҶжҲҗзҡ„ж–№жі•жӣҙеҠ еӨҚжқӮпјҢ并且иҜ„дј°дёҚеҗҢдҝЎжҒҜжәҗеҸҜйқ жҖ§зҡ„жңәеҲ¶д№ҹжӣҙеҠ е®Ңе–„гҖӮ
жЈҖзҙўеўһејәз”ҹжҲҗ (RAG) еә”иҝҗиҖҢз”ҹпјҢж—ЁеңЁи§ЈеҶіиҝҷдәӣжҢ‘жҲҳгҖӮRAG зі»з»ҹ并йқһд»…д»…дҫқиө–дәҺи®ӯз»ғиҝҮзЁӢдёӯеӯҰд№ еҲ°зҡ„еҸӮж•°пјҢиҖҢжҳҜе°ҶиҜӯиЁҖжЁЎеһӢзҡ„з”ҹжҲҗиғҪеҠӣдёҺеҸҜд»Ҙи®ҝй—®еӨ–йғЁзҹҘиҜҶжәҗзҡ„жЈҖзҙўжңәеҲ¶зӣёз»“еҗҲгҖӮ
е…ёеһӢзҡ„ RAG жһ¶жһ„е·ҘдҪңеҺҹзҗҶеҰӮдёӢпјҡ
зі»з»ҹжҺҘ收用жҲ·жҹҘиҜў
зі»з»ҹеңЁзӣёе…ізҹҘиҜҶеә“дёӯжҗңзҙўдёҺжҹҘиҜўзӣёе…ізҡ„дҝЎжҒҜ
зі»з»ҹе°ҶжҹҘиҜўе’ҢжЈҖзҙўеҲ°зҡ„дҝЎжҒҜиҫ“е…ҘиҜӯиЁҖжЁЎеһӢ
жЁЎеһӢж №жҚ®жЈҖзҙўеҲ°зҡ„дәӢе®һз”ҹжҲҗе“Қеә”
иҝҷз§Қж–№жі•е…·жңүд»ҘдёӢдјҳеҠҝпјҡ
еҹәдәҺз»ҸиҝҮйӘҢиҜҒзҡ„дҝЎжҒҜз”ҹжҲҗе“Қеә”пјҢд»ҺиҖҢиҺ·еҫ—жӣҙеҮҶзЎ®гҖҒжӣҙз¬ҰеҗҲдәӢе®һзҡ„е“Қеә”
иғҪеӨҹи®ҝй—®жЁЎеһӢи®ӯз»ғжҲӘжӯўеҖјд»ҘеӨ–зҡ„жңҖж–°дҝЎжҒҜ
д»Һе…¬еҸёж–ҮжЎЈзӯүзү№е®ҡйўҶеҹҹжқҘжәҗиҺ·еҸ–дё“дёҡзҹҘиҜҶ
йҖҡиҝҮеј•з”ЁдҝЎжҒҜжқҘжәҗе®һзҺ°йҖҸжҳҺеәҰе’ҢеҪ’еӣ
еҜ№дәҺе®һж–ҪеҜ№иҜқејҸ AI зҡ„дјҒдёҡиҖҢиЁҖпјҢRAG еңЁе®ўжҲ·жңҚеҠЎеә”з”Ёдёӯе·Іиў«иҜҒжҳҺе…·жңүзү№еҲ«зҡ„д»·еҖјгҖӮдҫӢеҰӮпјҢ银иЎҢиҒҠеӨ©жңәеҷЁдәәеҸҜд»Ҙи®ҝй—®жңҖж–°зҡ„дҝқеҚ•ж–Ү件гҖҒиҙҰжҲ·дҝЎжҒҜе’ҢдәӨжҳ“и®°еҪ•пјҢд»ҺиҖҢжҸҗдҫӣеҮҶзЎ®гҖҒдёӘжҖ§еҢ–зҡ„е“Қеә”пјҢиҖҢиҝҷеңЁзӢ¬з«Ӣзҡ„иҜӯиЁҖжЁЎеһӢдёӯжҳҜж— жі•е®һзҺ°зҡ„гҖӮ
RAG зі»з»ҹдёҚж–ӯеҸ‘еұ•пјҢжЈҖзҙўеҮҶзЎ®жҖ§дёҚж–ӯжҸҗй«ҳпјҢе°ҶжЈҖзҙўеҲ°зҡ„дҝЎжҒҜдёҺз”ҹжҲҗзҡ„ж–Үжң¬иҝӣиЎҢйӣҶжҲҗзҡ„ж–№жі•жӣҙеҠ еӨҚжқӮпјҢ并且иҜ„дј°дёҚеҗҢдҝЎжҒҜжәҗеҸҜйқ жҖ§зҡ„жңәеҲ¶д№ҹжӣҙеҠ е®Ңе–„гҖӮ
дәәжңәеҚҸдҪңжЁЎеһӢпјҡжүҫеҲ°жӯЈзЎ®зҡ„е№іиЎЎ
йҡҸзқҖеҜ№иҜқејҸдәәе·ҘжҷәиғҪеҠҹиғҪзҡ„жү©еұ•пјҢдәәдёҺдәәе·ҘжҷәиғҪзі»з»ҹд№Ӣй—ҙзҡ„е…ізі»д№ҹйҡҸд№Ӣжј”еҸҳгҖӮж—©жңҹзҡ„иҒҠеӨ©жңәеҷЁдәәиў«жҳҺзЎ®е®ҡдҪҚдёәе·Ҙе…·вҖ”вҖ”еҠҹиғҪжңүйҷҗпјҢдё”е…¶дәӨдә’ж–№ејҸжҳҺжҳҫйқһдәәзұ»еҢ–гҖӮзҺ°д»Јзі»з»ҹжЁЎзіҠдәҶиҝҷдәӣз•ҢйҷҗпјҢеј•еҸ‘дәҶе…ідәҺеҰӮдҪ•и®ҫи®Ўжңүж•Ҳзҡ„дәәжңәеҚҸдҪңзҡ„ж–°й—®йўҳгҖӮ
еҪ“д»ҠжңҖжҲҗеҠҹзҡ„еә”з”ЁжЎҲдҫӢйҒөеҫӘд»ҘдёӢеҚҸдҪңжЁЎеһӢпјҡ
дәәе·ҘжҷәиғҪеӨ„зҗҶж— йңҖдәәзұ»еҲӨж–ӯзҡ„常规гҖҒйҮҚеӨҚжҖ§жҹҘиҜў
дәәзұ»дё“жіЁдәҺйңҖиҰҒеҗҢзҗҶеҝғгҖҒйҒ“еҫ·жҺЁзҗҶжҲ–еҲӣйҖ жҖ§и§ЈеҶій—®йўҳзҡ„еӨҚжқӮжЎҲдҫӢ
зі»з»ҹдәҶи§ЈиҮӘиә«зҡ„еұҖйҷҗжҖ§пјҢ并еңЁйҖӮеҪ“зҡ„ж—¶еҖҷе№ізЁіең°еҚҮзә§еҲ°дәәе·Ҙе®ўжңҚ
з”ЁжҲ·еңЁдәәе·ҘжҷәиғҪе’Ңдәәе·Ҙе®ўжңҚд№Ӣй—ҙж— зјқеҲҮжҚў
дәәе·Ҙе®ўжңҚжӢҘжңүдёҺдәәе·ҘжҷәиғҪеҜ№иҜқзҡ„е®Ңж•ҙдёҠдёӢж–Ү
дәәе·ҘжҷәиғҪдёҚж–ӯд»Һдәәзұ»е№Ійў„дёӯеӯҰд№ пјҢйҖҗжӯҘжү©еұ•е…¶иғҪеҠӣ
иҝҷз§Қж–№жі•и®ӨиҜҶеҲ°пјҢеҜ№иҜқејҸдәәе·ҘжҷәиғҪзҡ„зӣ®ж Ү并йқһе®Ңе…ЁеҸ–д»ЈдәәжңәдәӨдә’пјҢиҖҢжҳҜеҜ№е…¶иҝӣиЎҢиЎҘе……вҖ”вҖ”еӨ„зҗҶеӨ§йҮҸиҖ—иҙ№дәәе·Ҙе®ўжңҚж—¶й—ҙзҡ„з®ҖеҚ•жҹҘиҜўпјҢеҗҢж—¶зЎ®дҝқеӨҚжқӮй—®йўҳиҺ·еҫ—еҗҲйҖӮзҡ„дәәе·Ҙ专家зҡ„и§Јзӯ”гҖӮ
жӯӨжЁЎеһӢзҡ„е®һж–Ҫеӣ иЎҢдёҡиҖҢејӮгҖӮеңЁеҢ»з–—дҝқеҒҘйўҶеҹҹпјҢдәәе·ҘжҷәиғҪиҒҠеӨ©жңәеҷЁдәәеҸҜд»ҘеӨ„зҗҶйў„зәҰе®үжҺ’е’Ңеҹәжң¬з—ҮзҠ¶зӯӣжҹҘпјҢеҗҢж—¶зЎ®дҝқеҢ»з–—е»әи®®жқҘиҮӘеҗҲж јзҡ„дё“дёҡдәәеЈ«гҖӮеңЁжі•еҫӢжңҚеҠЎйўҶеҹҹпјҢдәәе·ҘжҷәиғҪеҸҜд»Ҙеё®еҠ©еҮҶеӨҮе’Ңз ”з©¶ж–Ү件пјҢиҖҢе°Ҷи§ЈйҮҠе’Ңзӯ–з•ҘеҲ¶е®ҡдәӨз»ҷеҫӢеёҲгҖӮеңЁе®ўжҲ·жңҚеҠЎйўҶеҹҹпјҢдәәе·ҘжҷәиғҪеҸҜд»Ҙи§ЈеҶіеёёи§Ғй—®йўҳпјҢ并е°ҶеӨҚжқӮй—®йўҳиҪ¬дәӨз»ҷдё“дёҡе®ўжңҚдәәе‘ҳгҖӮ
йҡҸзқҖдәәе·ҘжҷәиғҪиғҪеҠӣзҡ„дёҚж–ӯжҸҗеҚҮпјҢйңҖиҰҒдәәе·ҘеҸӮдёҺе’ҢеҸҜд»ҘиҮӘеҠЁеҢ–зҡ„йўҶеҹҹд№Ӣй—ҙзҡ„з•Ңйҷҗе°ҶдјҡеҸ‘з”ҹеҸҳеҢ–пјҢдҪҶеҹәжң¬еҺҹеҲҷдҫқ然дёҚеҸҳпјҡжңүж•Ҳзҡ„еҜ№иҜқејҸдәәе·ҘжҷәиғҪеә”иҜҘеўһејәдәәзұ»зҡ„иғҪеҠӣпјҢиҖҢдёҚжҳҜз®ҖеҚ•ең°еҸ–д»Је®ғ们гҖӮ
еҪ“д»ҠжңҖжҲҗеҠҹзҡ„еә”з”ЁжЎҲдҫӢйҒөеҫӘд»ҘдёӢеҚҸдҪңжЁЎеһӢпјҡ
дәәе·ҘжҷәиғҪеӨ„зҗҶж— йңҖдәәзұ»еҲӨж–ӯзҡ„常规гҖҒйҮҚеӨҚжҖ§жҹҘиҜў
дәәзұ»дё“жіЁдәҺйңҖиҰҒеҗҢзҗҶеҝғгҖҒйҒ“еҫ·жҺЁзҗҶжҲ–еҲӣйҖ жҖ§и§ЈеҶій—®йўҳзҡ„еӨҚжқӮжЎҲдҫӢ
зі»з»ҹдәҶи§ЈиҮӘиә«зҡ„еұҖйҷҗжҖ§пјҢ并еңЁйҖӮеҪ“зҡ„ж—¶еҖҷе№ізЁіең°еҚҮзә§еҲ°дәәе·Ҙе®ўжңҚ
з”ЁжҲ·еңЁдәәе·ҘжҷәиғҪе’Ңдәәе·Ҙе®ўжңҚд№Ӣй—ҙж— зјқеҲҮжҚў
дәәе·Ҙе®ўжңҚжӢҘжңүдёҺдәәе·ҘжҷәиғҪеҜ№иҜқзҡ„е®Ңж•ҙдёҠдёӢж–Ү
дәәе·ҘжҷәиғҪдёҚж–ӯд»Һдәәзұ»е№Ійў„дёӯеӯҰд№ пјҢйҖҗжӯҘжү©еұ•е…¶иғҪеҠӣ
иҝҷз§Қж–№жі•и®ӨиҜҶеҲ°пјҢеҜ№иҜқејҸдәәе·ҘжҷәиғҪзҡ„зӣ®ж Ү并йқһе®Ңе…ЁеҸ–д»ЈдәәжңәдәӨдә’пјҢиҖҢжҳҜеҜ№е…¶иҝӣиЎҢиЎҘе……вҖ”вҖ”еӨ„зҗҶеӨ§йҮҸиҖ—иҙ№дәәе·Ҙе®ўжңҚж—¶й—ҙзҡ„з®ҖеҚ•жҹҘиҜўпјҢеҗҢж—¶зЎ®дҝқеӨҚжқӮй—®йўҳиҺ·еҫ—еҗҲйҖӮзҡ„дәәе·Ҙ专家зҡ„и§Јзӯ”гҖӮ
жӯӨжЁЎеһӢзҡ„е®һж–Ҫеӣ иЎҢдёҡиҖҢејӮгҖӮеңЁеҢ»з–—дҝқеҒҘйўҶеҹҹпјҢдәәе·ҘжҷәиғҪиҒҠеӨ©жңәеҷЁдәәеҸҜд»ҘеӨ„зҗҶйў„зәҰе®үжҺ’е’Ңеҹәжң¬з—ҮзҠ¶зӯӣжҹҘпјҢеҗҢж—¶зЎ®дҝқеҢ»з–—е»әи®®жқҘиҮӘеҗҲж јзҡ„дё“дёҡдәәеЈ«гҖӮеңЁжі•еҫӢжңҚеҠЎйўҶеҹҹпјҢдәәе·ҘжҷәиғҪеҸҜд»Ҙеё®еҠ©еҮҶеӨҮе’Ңз ”з©¶ж–Ү件пјҢиҖҢе°Ҷи§ЈйҮҠе’Ңзӯ–з•ҘеҲ¶е®ҡдәӨз»ҷеҫӢеёҲгҖӮеңЁе®ўжҲ·жңҚеҠЎйўҶеҹҹпјҢдәәе·ҘжҷәиғҪеҸҜд»Ҙи§ЈеҶіеёёи§Ғй—®йўҳпјҢ并е°ҶеӨҚжқӮй—®йўҳиҪ¬дәӨз»ҷдё“дёҡе®ўжңҚдәәе‘ҳгҖӮ
йҡҸзқҖдәәе·ҘжҷәиғҪиғҪеҠӣзҡ„дёҚж–ӯжҸҗеҚҮпјҢйңҖиҰҒдәәе·ҘеҸӮдёҺе’ҢеҸҜд»ҘиҮӘеҠЁеҢ–зҡ„йўҶеҹҹд№Ӣй—ҙзҡ„з•Ңйҷҗе°ҶдјҡеҸ‘з”ҹеҸҳеҢ–пјҢдҪҶеҹәжң¬еҺҹеҲҷдҫқ然дёҚеҸҳпјҡжңүж•Ҳзҡ„еҜ№иҜқејҸдәәе·ҘжҷәиғҪеә”иҜҘеўһејәдәәзұ»зҡ„иғҪеҠӣпјҢиҖҢдёҚжҳҜз®ҖеҚ•ең°еҸ–д»Је®ғ们гҖӮ
жңӘжқҘеүҚжҷҜпјҡеҜ№иҜқејҸдәәе·ҘжҷәиғҪзҡ„еҸ‘еұ•ж–№еҗ‘
еұ•жңӣжңӘжқҘпјҢдёҖдәӣж–°е…ҙи¶ӢеҠҝжӯЈеңЁеЎ‘йҖ еҜ№иҜқејҸдәәе·ҘжҷәиғҪзҡ„жңӘжқҘгҖӮиҝҷдәӣеҸ‘еұ•дёҚд»…жңүжңӣеёҰжқҘжёҗиҝӣејҸж”№иҝӣпјҢжӣҙеҸҜиғҪеҪ»еә•ж”№еҸҳжҲ‘们дёҺжҠҖжңҜдә’еҠЁзҡ„ж–№ејҸгҖӮ
еӨ§и§„жЁЎдёӘжҖ§еҢ–пјҡжңӘжқҘзҡ„зі»з»ҹдёҚд»…дјҡж №жҚ®еҪ“еүҚжғ…еўғпјҢиҝҳдјҡж №жҚ®жҜҸдёӘз”ЁжҲ·зҡ„жІҹйҖҡйЈҺж јгҖҒеҒҸеҘҪгҖҒзҹҘиҜҶж°ҙе№іе’Ңе…ізі»еҺҶеҸІжқҘе®ҡеҲ¶е“Қеә”гҖӮиҝҷз§ҚдёӘжҖ§еҢ–е°ҶдҪҝдәӨдә’жӣҙеҠ иҮӘ然гҖҒжӣҙе…·зӣёе…іжҖ§пјҢдҪҶд№ҹеј•еҸ‘дәҶе…ідәҺйҡҗз§Ғе’Ңж•°жҚ®дҪҝз”Ёзҡ„йҮҚиҰҒй—®йўҳгҖӮ
жғ…е•ҶпјҡиҷҪ然д»ҠеӨ©зҡ„зі»з»ҹеҸҜд»ҘжЈҖжөӢеҹәжң¬зҡ„жғ…з»ӘпјҢдҪҶжңӘжқҘзҡ„еҜ№иҜқејҸдәәе·ҘжҷәиғҪе°ҶеҸ‘еұ•еҮәжӣҙеӨҚжқӮзҡ„жғ…е•ҶвҖ”вҖ”иҜҶеҲ«еҫ®еҰҷзҡ„жғ…з»ӘзҠ¶жҖҒпјҢеҜ№з—ӣиӢҰжҲ–жІ®дё§еҒҡеҮәйҖӮеҪ“зҡ„еҸҚеә”пјҢ并зӣёеә”ең°и°ғж•ҙиҜӯж°”е’Ңж–№ејҸгҖӮиҝҷз§ҚиғҪеҠӣеңЁе®ўжҲ·жңҚеҠЎгҖҒеҢ»з–—дҝқеҒҘе’Ңж•ҷиӮІеә”з”Ёдёӯе°ӨдёәйҮҚиҰҒгҖӮ
дё»еҠЁеҚҸеҠ©пјҡдёӢдёҖд»ЈеҜ№иҜқејҸзі»з»ҹж— йңҖзӯүеҫ…жҳҺзЎ®зҡ„жҹҘиҜўпјҢиҖҢжҳҜдјҡж №жҚ®жғ…еўғгҖҒз”ЁжҲ·еҺҶеҸІи®°еҪ•е’ҢзҺҜеўғдҝЎеҸ·йў„жөӢйңҖжұӮгҖӮзі»з»ҹеҸҜиғҪдјҡжіЁж„ҸеҲ°жӮЁжӯЈеңЁдёҖдёӘйҷҢз”ҹзҡ„еҹҺеёӮе®үжҺ’еҮ еңәдјҡи®®пјҢ并主еҠЁжҸҗдҫӣдәӨйҖҡйҖүжӢ©жҲ–еӨ©ж°”йў„жҠҘгҖӮ
ж— зјқеӨҡжЁЎжҖҒйӣҶжҲҗпјҡжңӘжқҘзҡ„зі»з»ҹе°Ҷи¶…и¶Ҡз®ҖеҚ•ең°ж”ҜжҢҒдёҚеҗҢжЁЎжҖҒпјҢе®һзҺ°ж— зјқйӣҶжҲҗгҖӮеҜ№иҜқеҸҜд»ҘеңЁж–Үжң¬гҖҒиҜӯйҹігҖҒеӣҫеғҸе’ҢдәӨдә’е…ғзҙ д№Ӣй—ҙиҮӘ然жөҒз•…ең°иҝӣиЎҢпјҢдёәжҜҸжқЎдҝЎжҒҜйҖүжӢ©еҗҲйҖӮзҡ„жЁЎжҖҒпјҢиҖҢж— йңҖз”ЁжҲ·жҳҺзЎ®йҖүжӢ©гҖӮ
дё“дёҡйўҶеҹҹ专家пјҡиҷҪ然йҖҡз”ЁеҠ©жүӢе°ҶжҢҒз»ӯж”№иҝӣпјҢдҪҶжҲ‘们д№ҹе°ҶзңӢеҲ°й«ҳеәҰдё“дёҡеҢ–зҡ„еҜ№иҜқејҸдәәе·ҘжҷәиғҪзҡ„е…ҙиө·пјҢе®ғ们еңЁзү№е®ҡйўҶеҹҹжӢҘжңүж·ұеҺҡзҡ„дё“дёҡзҹҘиҜҶвҖ”вҖ”дҫӢеҰӮдәҶи§ЈеҲӨдҫӢжі•е’Ңе…ҲдҫӢзҡ„жі•еҫӢеҠ©зҗҶгҖҒе…ЁйқўдәҶи§ЈиҚҜзү©зӣёдә’дҪңз”Ёе’ҢжІ»з–—ж–№жЎҲзҡ„еҢ»з–—зі»з»ҹпјҢжҲ–зІҫйҖҡзЁҺжі•е’ҢжҠ•иө„зӯ–з•Ҙзҡ„иҙўеҠЎйЎҫй—®гҖӮ
зңҹжӯЈзҡ„жҢҒз»ӯеӯҰд№ пјҡжңӘжқҘзҡ„зі»з»ҹе°Ҷд»Һе®ҡжңҹеҶҚи®ӯз»ғиҪ¬еҗ‘д»Һдә’еҠЁдёӯжҢҒз»ӯеӯҰд№ пјҢйҡҸзқҖж—¶й—ҙзҡ„жҺЁз§»еҸҳеҫ—жӣҙжңүеё®еҠ©е’ҢдёӘжҖ§еҢ–пјҢеҗҢж—¶дҝқжҢҒйҖӮеҪ“зҡ„йҡҗз§ҒдҝқжҠӨгҖӮ
е°Ҫз®ЎеӯҳеңЁиҝҷдәӣд»Өдәәе…ҙеҘӢзҡ„еҸҜиғҪжҖ§пјҢдҪҶжҢ‘жҲҳдҫқ然еӯҳеңЁгҖӮйҡҗз§Ғй—®йўҳгҖҒеҮҸе°‘еҒҸи§ҒгҖҒйҖӮеҪ“зҡ„йҖҸжҳҺеәҰд»ҘеҸҠе»әз«ӢйҖӮеҪ“зҡ„дәәе·Ҙзӣ‘зқЈж°ҙе№іжҳҜжҢҒз»ӯеӯҳеңЁзҡ„й—®йўҳпјҢе®ғ们е°ҶеЎ‘йҖ иҝҷйЎ№жҠҖжңҜеҸҠе…¶зӣ‘з®ЎгҖӮжңҖжҲҗеҠҹзҡ„е®һж–Ҫе°ҶжҳҜйӮЈдәӣеңЁдёәз”ЁжҲ·жҸҗдҫӣзңҹжӯЈд»·еҖјзҡ„еҗҢж—¶пјҢиғҪеӨҹж·ұжҖқзҶҹиҷ‘ең°еә”еҜ№иҝҷдәӣжҢ‘жҲҳзҡ„ж–№жЎҲгҖӮ
жҳҫиҖҢжҳ“и§Ғзҡ„жҳҜпјҢеҜ№иҜқејҸдәәе·ҘжҷәиғҪе·Із»Ҹд»ҺдёҖйЎ№е°Ҹдј—жҠҖжңҜеҸ‘еұ•жҲҗдёәдё»жөҒз•ҢйқўиҢғејҸпјҢ并е°Ҷж—ҘзӣҠжҲҗдёәжҲ‘们дёҺж•°еӯ—зі»з»ҹдәӨдә’зҡ„еӘ’д»ӢгҖӮд»Һ ELIZA зҡ„з®ҖеҚ•жЁЎејҸеҢ№й…ҚеҲ°еҰӮд»ҠеӨҚжқӮзҡ„иҜӯиЁҖжЁЎеһӢпјҢиҝҷж®өжј”иҝӣд№Ӣи·Ҝд»ЈиЎЁзқҖдәәжңәдәӨдә’йўҶеҹҹжңҖйҮҚиҰҒзҡ„иҝӣжӯҘд№ӢдёҖвҖ”вҖ”иҖҢиҝҷж®өж—…зЁӢиҝңжңӘз»“жқҹгҖӮ
еӨ§и§„жЁЎдёӘжҖ§еҢ–пјҡжңӘжқҘзҡ„зі»з»ҹдёҚд»…дјҡж №жҚ®еҪ“еүҚжғ…еўғпјҢиҝҳдјҡж №жҚ®жҜҸдёӘз”ЁжҲ·зҡ„жІҹйҖҡйЈҺж јгҖҒеҒҸеҘҪгҖҒзҹҘиҜҶж°ҙе№іе’Ңе…ізі»еҺҶеҸІжқҘе®ҡеҲ¶е“Қеә”гҖӮиҝҷз§ҚдёӘжҖ§еҢ–е°ҶдҪҝдәӨдә’жӣҙеҠ иҮӘ然гҖҒжӣҙе…·зӣёе…іжҖ§пјҢдҪҶд№ҹеј•еҸ‘дәҶе…ідәҺйҡҗз§Ғе’Ңж•°жҚ®дҪҝз”Ёзҡ„йҮҚиҰҒй—®йўҳгҖӮ
жғ…е•ҶпјҡиҷҪ然д»ҠеӨ©зҡ„зі»з»ҹеҸҜд»ҘжЈҖжөӢеҹәжң¬зҡ„жғ…з»ӘпјҢдҪҶжңӘжқҘзҡ„еҜ№иҜқејҸдәәе·ҘжҷәиғҪе°ҶеҸ‘еұ•еҮәжӣҙеӨҚжқӮзҡ„жғ…е•ҶвҖ”вҖ”иҜҶеҲ«еҫ®еҰҷзҡ„жғ…з»ӘзҠ¶жҖҒпјҢеҜ№з—ӣиӢҰжҲ–жІ®дё§еҒҡеҮәйҖӮеҪ“зҡ„еҸҚеә”пјҢ并зӣёеә”ең°и°ғж•ҙиҜӯж°”е’Ңж–№ејҸгҖӮиҝҷз§ҚиғҪеҠӣеңЁе®ўжҲ·жңҚеҠЎгҖҒеҢ»з–—дҝқеҒҘе’Ңж•ҷиӮІеә”з”Ёдёӯе°ӨдёәйҮҚиҰҒгҖӮ
дё»еҠЁеҚҸеҠ©пјҡдёӢдёҖд»ЈеҜ№иҜқејҸзі»з»ҹж— йңҖзӯүеҫ…жҳҺзЎ®зҡ„жҹҘиҜўпјҢиҖҢжҳҜдјҡж №жҚ®жғ…еўғгҖҒз”ЁжҲ·еҺҶеҸІи®°еҪ•е’ҢзҺҜеўғдҝЎеҸ·йў„жөӢйңҖжұӮгҖӮзі»з»ҹеҸҜиғҪдјҡжіЁж„ҸеҲ°жӮЁжӯЈеңЁдёҖдёӘйҷҢз”ҹзҡ„еҹҺеёӮе®үжҺ’еҮ еңәдјҡи®®пјҢ并主еҠЁжҸҗдҫӣдәӨйҖҡйҖүжӢ©жҲ–еӨ©ж°”йў„жҠҘгҖӮ
ж— зјқеӨҡжЁЎжҖҒйӣҶжҲҗпјҡжңӘжқҘзҡ„зі»з»ҹе°Ҷи¶…и¶Ҡз®ҖеҚ•ең°ж”ҜжҢҒдёҚеҗҢжЁЎжҖҒпјҢе®һзҺ°ж— зјқйӣҶжҲҗгҖӮеҜ№иҜқеҸҜд»ҘеңЁж–Үжң¬гҖҒиҜӯйҹігҖҒеӣҫеғҸе’ҢдәӨдә’е…ғзҙ д№Ӣй—ҙиҮӘ然жөҒз•…ең°иҝӣиЎҢпјҢдёәжҜҸжқЎдҝЎжҒҜйҖүжӢ©еҗҲйҖӮзҡ„жЁЎжҖҒпјҢиҖҢж— йңҖз”ЁжҲ·жҳҺзЎ®йҖүжӢ©гҖӮ
дё“дёҡйўҶеҹҹ专家пјҡиҷҪ然йҖҡз”ЁеҠ©жүӢе°ҶжҢҒз»ӯж”№иҝӣпјҢдҪҶжҲ‘们д№ҹе°ҶзңӢеҲ°й«ҳеәҰдё“дёҡеҢ–зҡ„еҜ№иҜқејҸдәәе·ҘжҷәиғҪзҡ„е…ҙиө·пјҢе®ғ们еңЁзү№е®ҡйўҶеҹҹжӢҘжңүж·ұеҺҡзҡ„дё“дёҡзҹҘиҜҶвҖ”вҖ”дҫӢеҰӮдәҶи§ЈеҲӨдҫӢжі•е’Ңе…ҲдҫӢзҡ„жі•еҫӢеҠ©зҗҶгҖҒе…ЁйқўдәҶи§ЈиҚҜзү©зӣёдә’дҪңз”Ёе’ҢжІ»з–—ж–№жЎҲзҡ„еҢ»з–—зі»з»ҹпјҢжҲ–зІҫйҖҡзЁҺжі•е’ҢжҠ•иө„зӯ–з•Ҙзҡ„иҙўеҠЎйЎҫй—®гҖӮ
зңҹжӯЈзҡ„жҢҒз»ӯеӯҰд№ пјҡжңӘжқҘзҡ„зі»з»ҹе°Ҷд»Һе®ҡжңҹеҶҚи®ӯз»ғиҪ¬еҗ‘д»Һдә’еҠЁдёӯжҢҒз»ӯеӯҰд№ пјҢйҡҸзқҖж—¶й—ҙзҡ„жҺЁз§»еҸҳеҫ—жӣҙжңүеё®еҠ©е’ҢдёӘжҖ§еҢ–пјҢеҗҢж—¶дҝқжҢҒйҖӮеҪ“зҡ„йҡҗз§ҒдҝқжҠӨгҖӮ
е°Ҫз®ЎеӯҳеңЁиҝҷдәӣд»Өдәәе…ҙеҘӢзҡ„еҸҜиғҪжҖ§пјҢдҪҶжҢ‘жҲҳдҫқ然еӯҳеңЁгҖӮйҡҗз§Ғй—®йўҳгҖҒеҮҸе°‘еҒҸи§ҒгҖҒйҖӮеҪ“зҡ„йҖҸжҳҺеәҰд»ҘеҸҠе»әз«ӢйҖӮеҪ“зҡ„дәәе·Ҙзӣ‘зқЈж°ҙе№іжҳҜжҢҒз»ӯеӯҳеңЁзҡ„й—®йўҳпјҢе®ғ们е°ҶеЎ‘йҖ иҝҷйЎ№жҠҖжңҜеҸҠе…¶зӣ‘з®ЎгҖӮжңҖжҲҗеҠҹзҡ„е®һж–Ҫе°ҶжҳҜйӮЈдәӣеңЁдёәз”ЁжҲ·жҸҗдҫӣзңҹжӯЈд»·еҖјзҡ„еҗҢж—¶пјҢиғҪеӨҹж·ұжҖқзҶҹиҷ‘ең°еә”еҜ№иҝҷдәӣжҢ‘жҲҳзҡ„ж–№жЎҲгҖӮ
жҳҫиҖҢжҳ“и§Ғзҡ„жҳҜпјҢеҜ№иҜқејҸдәәе·ҘжҷәиғҪе·Із»Ҹд»ҺдёҖйЎ№е°Ҹдј—жҠҖжңҜеҸ‘еұ•жҲҗдёәдё»жөҒз•ҢйқўиҢғејҸпјҢ并е°Ҷж—ҘзӣҠжҲҗдёәжҲ‘们дёҺж•°еӯ—зі»з»ҹдәӨдә’зҡ„еӘ’д»ӢгҖӮд»Һ ELIZA зҡ„з®ҖеҚ•жЁЎејҸеҢ№й…ҚеҲ°еҰӮд»ҠеӨҚжқӮзҡ„иҜӯиЁҖжЁЎеһӢпјҢиҝҷж®өжј”иҝӣд№Ӣи·Ҝд»ЈиЎЁзқҖдәәжңәдәӨдә’йўҶеҹҹжңҖйҮҚиҰҒзҡ„иҝӣжӯҘд№ӢдёҖвҖ”вҖ”иҖҢиҝҷж®өж—…зЁӢиҝңжңӘз»“жқҹгҖӮ





